clear all
set more off
cd "C:/StataClass/chap_file"
. clear all
. set more off
. cd "C:/StataClass/chap_file"
C:\StataClass\chap_file
. 从本章开始,我们将正式进入Stata数据分析及应用的课程,作为课程的起始部分,我们将学习如何处理“数据文件”。
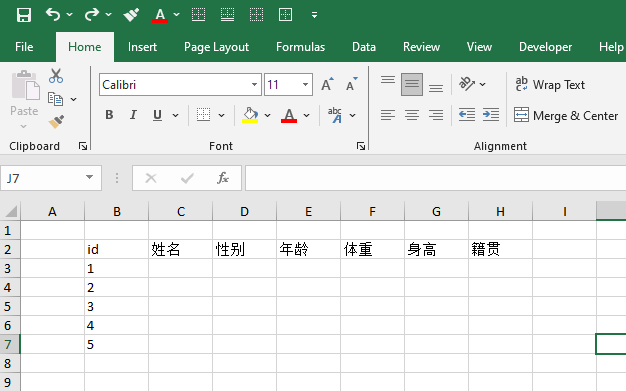
数据是对一些“对象”的“特征”的描述的集合,例如我们想要观察在座的各位同学的基本信息:身高、年龄、体重、籍贯。这时候,每一位同学就构成了一个个的观测对象,有时候也被称为样本点、而身高、年龄这些信息则是不同的特征,有时候也被称为是“特征”、“变量”、“属性”,记录和展示所有同学的这些信息的文件就是数据文件。文件可以有不同的格式,数据也就有了不同的载体。相信大家都有使用Excel/WPS等电子表格软件记录和处理数据的经历,我们可以用下面这种“结构”来表示上面的这一数据:
在前面的章节/课程中我们曾经提到过,Stata中使用的数据文件是以后缀名.dta结尾的文件,这种文件本质上这是一个二进制文件,能够(在Stata中)较快速度的读写,需要用Stata软件进行读写(也就是只能由Stata识别和处理)。
在本章中,我们将学习Stata中的文件操作,包括如何将常见的数据文件格式转换为Stata格式的数据文件、以及对数据文件进行简单的操作,具体的问题如下:
本节中,我们将首先介绍推荐的文件目录结构,它对于后续课程的学习也很重要。 然后我们将学习如何从数据库中下载数据。结合我校的电子资源购买情况,大家需要学习色诺芬数据库(CCER)、巨灵数据库(EPS)和国家统计局官网下载数据。本章我们将只会涉及到CCER和国家统计局网站的数据下载。
接下来每次的课程中,我们大多都会涉及到一些数据文件的处理,也会编写一些代码文件。推荐大家首先新建一个课程的根目录,例如C:/StataClass,然后每个章节新建一个子目录,当前章节为文件操作,所以我们在C:/StataClass新建一个chap_file的文件夹,本周所有的代码和数据文件可以都放在这个文件夹内(当然你也可以再细分建立诸如data、code等子文件夹,但对于目前我们的数据处理来说,由于文件内容不多,可以先不这样做)。
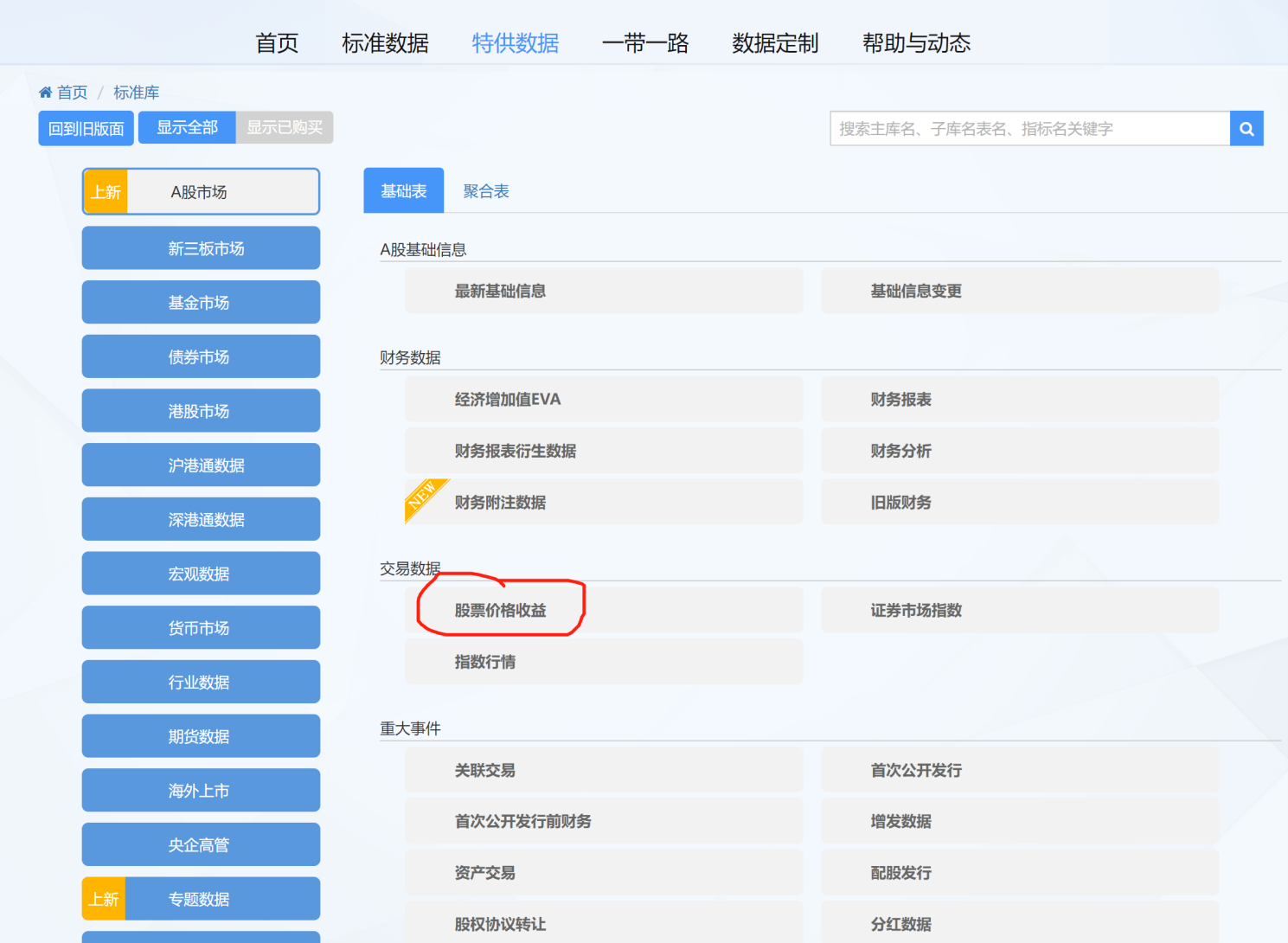
请将课程QQ群内的数据文件stock_trade_data202101.xlsx、index_trade_data202101.xlsx、GDP1978-2022.xls(群文件——data)下载并放置在C:/StataClass/chap_file下。
原始数据大多来自于数据库中已经整理好的数据,且大多为格式化的数据。这些数据文件是我们进行数据分析的起点。尽管本课程并不要求大家掌握如何获取数据,所有需要大家处理的原始数据都会为大家提前准备好(例如可以从课程的QQ群下载),但获取数据本身也是一项非常重要的技能,本章的附录2.13.2和附录2.13.3部分,向大家展示了如何在CCER数据库和国家统计局下载数据,大家可以自行参照学习。
大家获得的原始数据文件的类型多为Excel文件(后缀名为.xls或者.xlsx)或者文本文件(后缀名为.csv、.txt最为常见)。文本文件具有通用性强、空间占用小等优点;Excel文件可以避免数据格式、编码等大家不太熟悉的问题导致的混乱。大多数情况下(特别是你处理的文件数据量不大、也不需要在不同类型的操作系统之间切换工作),更推荐大家使用Excel格式的原始数据;如果数据量太多(数据文件很大,例如超过500MB),或者你知道应该使用UTF-8编码或GBK编码避免不同系统下中文乱码问题,更推荐大家使用文本文件作为原始数据。 本课程中,我们的原始数据绝大多数都是Excel文件。
为了使用文本文件表示一些结构化的类似Excel中的二维表数据,我们通常有一些“约定俗成”的做法。常见的文本文件格式包括:以逗号分隔的文本文件(comma delimited text file)、以制表符分隔的文本文件(tab delimted text files)。例如后缀名csv是comma seperated values,即逗号分隔的值。这种文件是纯文本文件,结构相对简单,通常由以下组成:
' 或双引号 ")将这个数据包围起来,防止误认为是两个不同数据。类似于csv文件,还有一种使用制表符分隔的文本文件,通常以txt结尾,与CSV文件的差异在于不是以逗号分隔数据,而是以制表符 tab (通常是用若干个空格来实现)来分隔数据。
其实,我们只需要规定好用什么符号作为换行(行)、用什么符号作为分隔符(列),就可以使用文本文件表示结构化的数据了。
我们可以使用Microsoft Excel(或者WPS)将excel格式的数据文件另存为csv或者txt格式的文本文件。
在do文件的开头处,加入如下代码:
clear all
set more off
cd "C:/StataClass/chap_file"
. clear all
. set more off
. cd "C:/StataClass/chap_file"
C:\StataClass\chap_file
. 上面的代码在上一章引言章节中都有介绍,三行代码的功能分别是:将内存情况、自动滚屏显示结果和切换工作目录到C:/StataClass/chap_file下(工作目录会显示在Stata的主窗口左下角,如果上述代码执行通通过,可以看到在主界面中左下角的位置,会提示工作目录已经从当前用户的文档目录切换到了C:/StataClass/chap_file下。
需要指出的是,我们无须频繁切换工作目录,在下一次切换工作目录前,Stata的工作目录都会保持在已经设定的目录之下,通常我们在代码开始的位置切换工作目录,此后如无必要,将不再切换。
Excel格式的文件和文本文件都是我们常见的原始数据格式,使用Excel的优点是不用受到诸如文件编码、换行符等问题的困扰,缺点是文件较大、读取速度慢、依赖于Excel软件作为底层转换的工具,如果你的电脑上没有安装MS office或者WPS office,可能会导致Stata读入Excel数据报错。
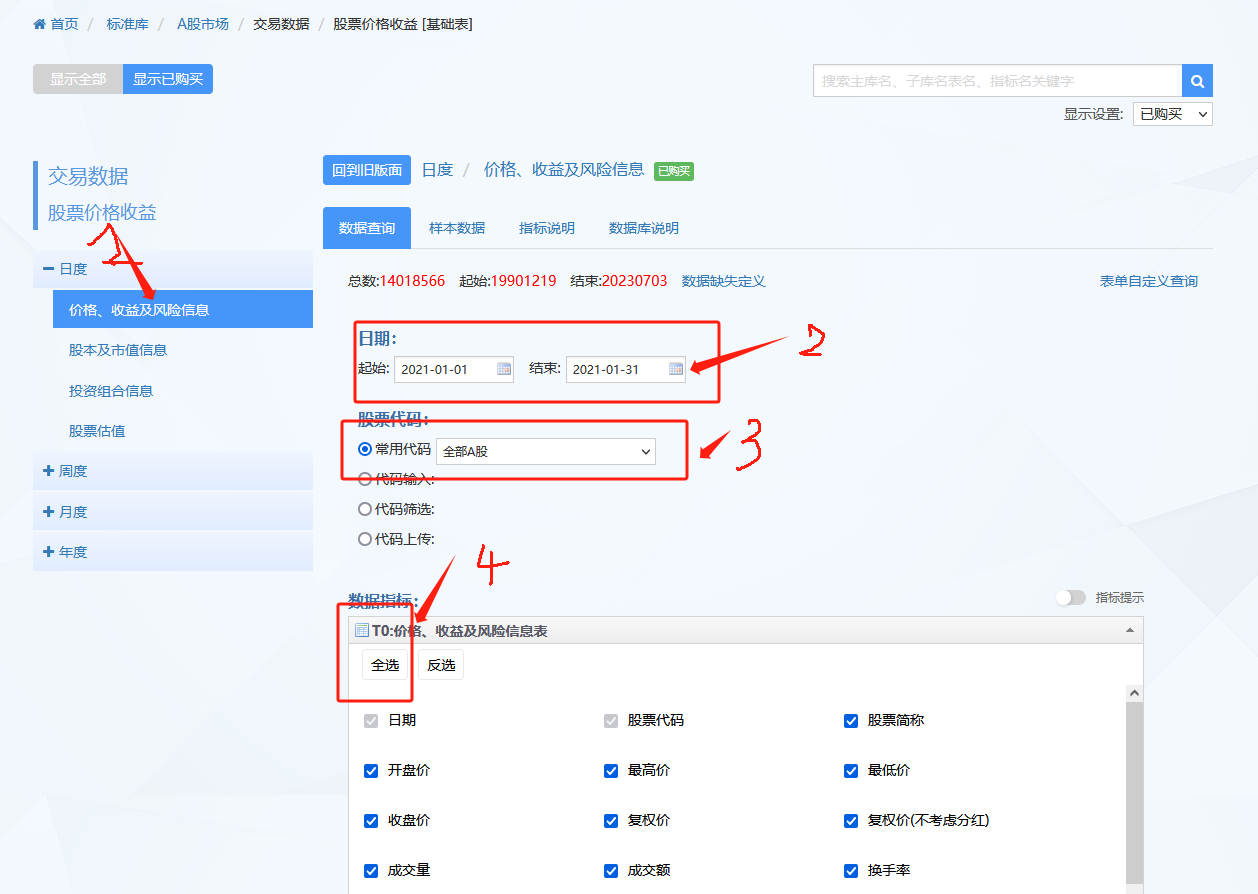
以导入stock_trade_data202101.xlsx文件为例,我们基于命令import excel实现数据的导入,可以通过help import excel查看帮助文档。
import excel using "./stock_trade_data202101.xlsx", clear //读入excel文件
describe
browse上述代码中最核心的命令是 import excel using "./stock_trade_data202101.xlsx", clear,import excel指示读入excel文件,using和后面的文件名称指示了具体要读入的Excel文件。需要指出的是,这里./是指当前目录,结合上面的cd...命令,当前目录就是C:/StataClass/week31。这里文件的路径我们使用了引号将路径和文件名包围了起来,这是为了防止文件名称或者文件所在路径中出现空格2。接下来是一个逗号可选项(option):clear,与命令的主体之间使用逗号,隔开。clear的功能是在import读入数据之前清空内存中的数据。
在Stata中,一条命令可以通过逗号(comma)分隔开来,前半部分是命令的主体(body),后半部分是命令的选项(option),option可以为命令主体提供更加丰富多样的功能。 我们将在后续章节中系统学习Stata的命令结构。
第一章中,我们曾介绍过Stata中的clear命令和clear all命令,它们可以清空Stata中已有的数据和其他信息(如果已有的话),这里的clearoption实现了类似的功能,它与两条命令连用:clear和import excel ...是等价的,这样的写法更加简洁。
另外,在Stata中,之所以要引入清空数据的概念,主要是为了防止对数据集的误操作。我们曾经提到过,Stata中默认能够处理的数据集只有一个,如果你对这个数据做了一些修改,但是在将数据保存到硬盘之前就想要读入新的数据到内存中,这会导致原来的文件被覆盖,所有的改动都将消失,因此这是“有风险”的操作,因此Stata会要求你显式地给出指令,“我不想要这个没保存的数据了,我的确需要把这个数据清空,读入新的数据”。类似的逻辑我们还将会在保存数据的命令save中再次看到。
上面读入Excel文件后还出现了两个命令:
describe命令第一章已经介绍过,会给出当前数据集的基本信息。
browse命令是在数据浏览窗口中打开当前数据集,你将会看到Stata弹出了一个新的窗口,类似与Excel中的二维表结构,它直观展示了数据的内容,每一列是一个变量,每一行是一条观测值,代表了某个个体在全部变量上的观测值。
Stata默认只能处理一个数据集,数据集的内容就是通过数据浏览器(Data Editor)看到的样子,每一列是一个变量,每一行是一条观测值,代表了某个个体在全部变量上的观测值 。我们还可以通过主界面任务栏上的两个图标  打开数据浏览器窗口查看数据,左边的按钮同样会打开数据浏览器,但是是在编辑模式下,数据的内容可以修改对应
打开数据浏览器窗口查看数据,左边的按钮同样会打开数据浏览器,但是是在编辑模式下,数据的内容可以修改对应edit命令;右侧的按钮是在只读模式下打开数据浏览器窗口,无法修改数据内容,对应browse命令。
推荐大家使用browse而不是edit,对数据的修改应该尽可能使用代码来完成,让所有的改动有据可查、方便回溯、可以重复。
但是原始数据中的第一行本来是变量的提示信息,现在也作为数据被读入进来了(被当做了数据的第一行),更合理的方案是把这一行信息作为变量的变量命或者标签(label)或者直接将第一行信息舍弃,不作为数据读入。我们会在后续学习了循环控制语句后,回过头来通过手动编写代码的形式,实现将第一行数据作为变量标签进行保存,在这里我们首先将第一行作为变量名保存下来。
import excel using "./stock_trade_data202101.xlsx", clear firstrow相比于前面的代码,我们增加了一个option:firstrow,通过阅读help文档,这个option的功能是treat first row of Excel data as variable names。请重新执行这条命令,并通过browse和describe命令查看新添加这个option后的效果。
最后,我们再来对上面的命令做一点改动:
import excel using "./stock_trade_data202101.xlsx", clear cellrange(A2)唯一的差别是将firstrow这一option删除,替换成了cellrange(A2),通过查阅帮助文档,可以知道cellrange([start] [:end])的作用指定读入数据起止范围,在本文的例子中,cellrange(A2)指定数据从A2单元格开始的全部数据。
大家也许知道一个Excel文件中允许有不同的sheet,例如数据文件stock_trade_data202101.xlsx中只有一个sheet,名为data。当Excel文件中有多个sheet且我们需要读入的数据不在第一个活动sheet中,那么我们还需要指定sheet名称,这样才能定位数据:
import excel using "./stock_trade_data202101.xlsx", clear sheet("Data") firstrow回到本文的例子,读入stock_trade_data202101.xlsx文件,通过如下命令,可以将第一行作为变量名读入,是处理excel文件的推荐方案(当然这并不意味着所有的情况下都是将第一行作为变量名,需要具体问题具体分析):
cd "C:/StataClass/chap_file"
import excel using "./stock_trade_data202101.xlsx", clear firstrow
describe // 数据描述
browse // 查看数据有时候当尝试导入Stata的Excel文件太大时,会有报错提示file xxxx.xlsx too big,这是由于Stata对于读入的Excel大小有一个缺省的大小限制,可以在读入数据前增加如下命令来解决这个限制问题:
set excelxlsxlargefile on当然,也可以不使用Excel文件,换用文本格式的数据文件。
我们可以使用CSV作为原始数据的文件读入Stata,相比之下,使用文本文件读入数据的速度比Excel文件的读入速度更快。与读入Excel文件的命令类似,我们使用import delimited命令读入文件(可以通过help import delimited查看帮助文档),具体如下:
cd "C:/StataClass/chap_file"
import delimited using "./stock_trade_data202101-utf8.csv", clear delimiters(",") varname(1) encoding("utf8")
describe
browse相比前一小节使用的import excel命令,我们这里使用的import delimited有几点不同:
delimiters(","):指示了文本文件中的分隔符是逗号(英文输入状态下)3,如果是制表符分隔的文本文件,括号内则需要改成"\t"。(\是转义字符,\t代表制表符,即键盘上的tab键)。varname(1):指示了将数据文件的第1行作为变量名称。encoding("utf8"):指示了数据文件的编码方式(我们为大家提供的csv文件是UTF8编码,如果是在windows操作系统中生成的,编码可能是gbk或者gb18030)。当然import delimited 还有很多其他的可选option,可以实现更加复杂的命令和更加精确的控制,感兴趣的同学请通过官方帮助文档自主学习。
Stata中使用dta文件作为数据文件的格式,我们可以使用命令save将当前的数据集保存到硬盘中,例如我们将导入的stock_trade_data202101-utf8.csv保存为dta格式的数据文件,可以通过如下命令完成:
cd "C:/StataClass/chap_file"
import excel using "./stock_trade_data202101.xlsx", clear firstrow
save "./stock_trade_data202101.dta", replace
. cd "C:/StataClass/chap_file"
C:\StataClass\chap_file
. import excel using "./stock_trade_data202101.xlsx", clear firstrow
(26 vars, 78,452 obs)
. save "./stock_trade_data202101.dta", replace
file ./stock_trade_data202101.dta saved
. save后紧跟的是要保存的文件的路径和文件名,作用是将当前的数据保存到硬盘指定的位置去。与前面导入数据文件一样,./代表当前目录(工作目录),其实就是C:/StataClass/week3。仍然是出于防止目录或者文件名中存在空格的考虑,我们在路径上使用了双引号。可选项replace为了应对多次重复运行代码时目标文件已经存在的报错。你可以尝试将, replace去掉,然后重新运行这条save命令至少2次,你会发现主界面会有报错提示:file ./stock_trade_data202101.dta already exists。这是因为在软件看来,硬盘上的文件夹中已经有文件stock_trade_data202101.dta存在,此时保存文件是有风险的:可能会覆盖已有的文件。replace这一可选项的功能就是告诉软件:如果对应的文件在硬盘上已经存在,就用新的文件覆盖原来的文件。
接下来,我们将会多次使用到数据集stock_trade_data202101.dta
在前面的数据处理中,我们可以使用import excel和import delimited 命令将外部数据文件导入到Stata中,并通过save命令将数据保存为硬盘上的dta文件。
我们通过use命令可以打开本地的dta文件,将文件从硬盘导入到内存,例如可以通过如下命令将刚才保存的dta文件打开:
clear //清空内存中的数据
use "./stock_trade_data202101.dta"
browse当然也可以将clear与use ...的代码合并为一行:
use "./stock_trade_data202101.dta", clear 在第一章中,我们还介绍过使用sysuse命令读入系统自带的dta文件,sysuse和use都是读入dta格式的文件,区别在与sysuse会从特定的位置读取系统自带的dta格式的数据文件。而use命令可以读取任意位置的dta格式的数据文件。你可以通过如下命令来体会:
// 方案1 sysuse命令
sysuse auto.dta, clear
//
// 方案2 use+文件精确地址
use "C:/Program Files/Stata17/ado/base/a/auto.dta", clear
//
//方案3:首先切换工作目录到系统目录下(不推荐)
cd "C:/Program Files/Stata17/ado/base/a"
use auto.dta, clear
cd "C:/StataClass/chap_file" // 重新切换工作目录虽然方案2和方案3都是可行方案,但是并不建议大家这样做,如果是使用自带的数据文件,尽量通过sysuse命令,而且也不要对系统的目录进行修改操作。
目前,无论是导入外部数据还是读入dta数据,我们的数据都是存放在本地(当前电脑的计算机硬盘上),如果数据放在服务器上,也是可以通过网络读取的,只不过这个文件的位置是一个网络上的地址。
例如,我们use+服务器网址+文件名的方式打开dta格式的数据文件,如果没有指定网络文件的位置,那么将默认从http://www.stata-press.com/data/r17这一位置获取数据。Stata公司将很多数据放在http://www.stata-press.com/data/ 目录下,这里存放了StataManual(手册)中用到的数据、Stata出版的书籍中用到的数据。通过以下命令可以打开官方nlswork.dta数据:
use "http://www.stata-press.com/data/r17/nlswork.dta", clear
webuse nlswork, clear事实上,只要数据存放的网络是开放访问的,我们自己的dta文件、文本格式的文件也可以打开 我已经将数据存放在了一个开源代码托管网站(Gitee),可以通过网址https://gitee.com/znxkxx/stata2023/raw/master/week3/GDP1978-2022.csv打开stock_trade_data202101-utf8.csv。你可以通过该项目所在的Repo查看所有存放的数据:https://gitee.com/znxkxx/stata2023
import delimited using "https://gitee.com/znxkxx/stata2023/raw/master/week3/stock_trade_data202101-utf8.csv", clear
use "https://gitee.com/znxkxx/stata2023/raw/master/week3/stock_trade_data202101.dta", clear 数据的拆分分为两种:横向拆分和纵向拆分。所谓横向拆分是指保留数据中的部分观测值(按照一定的条件);纵向拆分是指减少部分变量。
纵向拆分的示意图如下:
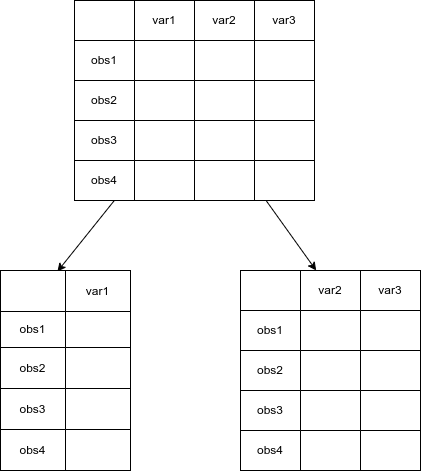
使用命令drop varlist 可以实现纵向切割、也就是删除部分变量的目标,这里varlist是变量列表(variable list)的意思,例如drop var1就是删除一个名为var1的变量,同时删除多个变量时,不同变量依次列出,中间以空格分隔,例如drop var1 var2 例如,针对2021年的股票日收益率数据文件”stock_trade_data202101.dta”,假设我们要删除最高价和最低价两个变量,可以用如下命令:
use "stock_trade_data202101.dta", clear
describe
drop 最高价 最低价 // 删除最高价和最低价两个变量
describe
keep 日期 股票代码 股票简称 开盘价 收盘价 //仅保留 若干感兴趣的变量
describe横向拆分的示意图如下:
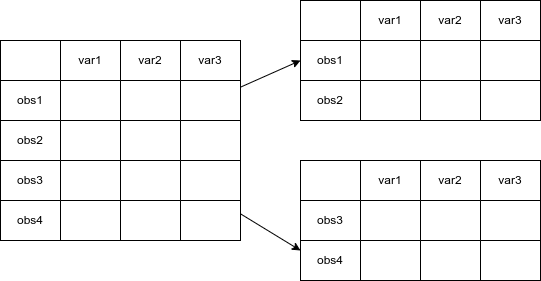
使用drop命令加上 if exp(if语句)可以实现将按照表达式(expression)所代表的条件(逻辑)删除部分观测值。例如,针对2021年的股票日收益率数据文件”stock_trade_data202101.dta”,假设我们删除收盘价高于50元的数据,可以用如下命令:
use "stock_trade_data202101.dta", clear
destring 收盘价, replace // 将收盘价变量从字符型转为数值型
summarize 收盘价
display _N // 显示(输出)现有的数据量
drop if 收盘价> 50
summarize 收盘价
di _N 数据stock_trade_data202101.dta是我们在 小节 2.4.1 从excel文件生成的dta文件。所有的变量都被保存成了“字符型”变量,命令 destring 收盘价, replace 可以将变量收盘价从字符转换为数值,例如从"18.2600"转换为18.26。
我们会在后续章节中详细介绍字符、字符变量以及字符与数值之间的互相转换。
通过这段代码可以看到数据的观测值变少了,当然也可以通过browse命令或者主窗口下Properties-Data看出来。 当然除了drop if 之外,drop in 也能起到类似的纵向拆分功能。例如删除第一行、第二行、删除前5行、删除最后5行数据的代码如下:
sysuse auto, clear
drop in 1
drop in 2
drop in 1/5
drop in -5/-1
sysuse auto, clear
drop if _n == 1
drop if _n == 2
drop if _n >= 1 & _n <= 5
drop if _n > (_N - 5) _n和_N
在Stata的数据集中,_N是一个常数,代表当前数据集的总行数,例如对于系统自带的auto.dta数据文件一共有74行,则_N=74。_n则对应每一行的行号,第k行(k=1,2,\cdots,_N)数据的_n取值为k。_n的取值也是常量,只不过是每一行对应一个取值。
==和=
在Stata的语法中,一个等号=代表的是赋值符号,两个等号==才是逻辑相等判断符号,初学者经常会错误的在需要双等号时写成了单等号。
命令drop if _n >=-5 & _n <= -1能否像drop in -5/-1一样实现“删除最后5行”的功能?为什么?
我们还可以根据股票名称筛选出特定股票的交易数据,例如下面的例子会删除股票简称不是”青岛啤酒”的观测值,换言之也就是仅保留了“青岛啤酒”这支股票的交易数据:
use "stock_trade_data202101.dta", clear
drop if 股票简称 != "青岛啤酒" //删除股票简称不是"青岛啤酒"的观测值
save "青岛啤酒_交易数据.dta",replace 代码drop if 股票简称 != "青岛啤酒"的含义是删除满足条件股票简称 != "青岛啤酒"的观测值,!=符号是逻辑“不等于”(逻辑等于符号是==),这部分关于逻辑表达式的内容我们将会在条件语句的章节更进一步学习。这一逻辑判断是按照数据的“行”逐行进行的:首先看第一行的数据,看是否满足 股票简称 != "青岛啤酒",如果满足就执行drop,如果不满足就跳过;然后是第二行、第三行……直到最后一行(即第_N行)。
另一个需要注意的地方在于,当变量的取值是字符型(例如上面这个例子中stock_trade_data202101.dta中的股票简称变量)时,如果要判断字符型变量的取值是否满足某些条件,需要将内容用双引号引起来。如果这句话写成drop if 股票简称 != 青岛啤酒,代码的含义就变成了:删除股票简称变量与青岛啤酒变量的取值相同的观测值,换言之,青岛啤酒如果不加引号会被识别为一个变量名,而加了引号后,会被(正确地,本例中)识别为字符串。
文件数据的合并是指将两个数据文件合并成一个数据文件的操作。前面我们提到过,Stata在默认状态下只能处理一个数据集,所以如果要将两个文件合并,我们通常是将正在处理中的数据(内存中的使用中的数据——using data和硬盘上的外部数据outside data进行合并。
Stata中的数据文件操作大致有如下几个命令:merge,append,xpose,reshape,joinby和cross,它们的含义如下:
| 命令 | 解释 | 原理 |
|---|---|---|
| append | 纵向合并 | 数据的观测值数量增加,例如将2021年股票交易数据和2022年的股票交易数据合并在一起 |
| xpose | 行列转置 | 类似线性代数中矩阵的转置操作 |
| merge | 横向合并 | 数据的变量增加,例如将2021年股票的股票交易数据和2021年上市公司的财务数据合并在一起 |
| reshape | 数据形变 | 将面板数据类型转换为截面数据类型 |
| joinby | 多对多合并 | 不多见 |
| cross | 逐行的两两合并 | 不多见 |
较为常用的是append, merge和reshape,对应的操作是纵向合并、横向合并与长宽转换。需要重点掌握好这三类数据文件的合并操作。
纵向合并append的原理如下图所示,即将两个结构类似的文件合并在一起,通常用于增加数据的样本量(观测值),对应的逻辑关系图如下:
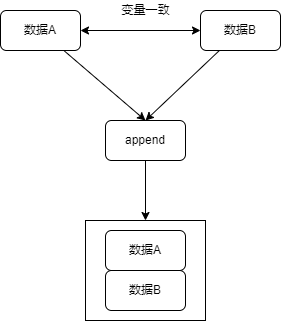
以合并2021年1月4日stock_trade_data和2021年1月5日stock_trade_data为例,逻辑为:读入2021年1月4日的数据并保存为dta文件\rightarrow读入2021年1月5日的数据并保存为dta文件\rightarrow重新将2021年1月5日的数据读入内存\rightarrow合并2021年2月的数据。代码如:
cd "C:/StataClass/chap_file"
// 读取2021年1月的交易数据
use "stock_trade_data202101.dta", clear
// 保留1月4日的数据
keep if 日期 == "20210104"
save "stock_daily_return_20210104.dta", replace
// 读取2021年1月的交易数据
use "stock_trade_data202101.dta", clear
// 保留1月5日的数据
keep if 日期 == "20210105"
save "stock_daily_return_20210105.dta", replace
// 合并
use "stock_daily_return_20210104.dta", clear
append using "stock_daily_return_20210105.dta"
save "stock_daily_return_202101_04to05.dta", replace 下面的代码能否实现合并的功能呢?可能存在什么问题?
cd "C:/StataClass/chap_file"
use "stock_trade_data202101.dta", clear
keep if 日期 == "20210104"
save "stock_daily_return_20210104.dta", replace
use "stock_trade_data202101.dta", clear
keep if 日期 == "20210105"
save "stock_daily_return_20210105.dta", replace
append using "stock_daily_return_20210105.dta"
save "stock_daily_return_202101_04to05.dta", replace 横向合并merge将内存中现有的数据与硬盘中的另一个数据(必须是dta格式)横向合并。它的原理如下图所示,即将两个少数变量一样的两个文件合并在一起,通常用于增加数据的变量数量。
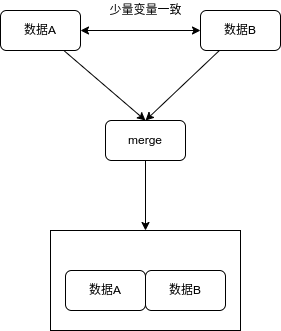
合并的命令是merge,它的功能是将内存中现有的数据和硬盘中的另一个.dta文件横向合并在一起。横向合并有三种类型:1对1合并(1:1)、一对多合并(1:m,或m:1)、多对多合并(m:m),其中前两种是推荐大家使用的合并方式,第三种不推荐在任何场合使用,多对多的合并采用joinby命令。merge的横向合并需要一个关键词,也就是通过哪(几)个变量把两个文件关联起来。
与append命令不同,merge命令中被合并的两个文件通常是两个不同该类型的文件,它们的变量基本都不相同,例如一个文件描述的是商品的价格,另一个文件是描述的商品的数量。
假设我们有两个数据集,其中已经读入了描述个体年龄的文件(master in memory),另有一个描述个体重量的文件存储在硬盘上。

我们的目标是把这两个文件合并在一起,得到一个新的文件,这个文件将拥有三个变量,id, age, wgt。注意看,id这个变量在两个数据文件中都是可以唯一识别数据的观测值,也就是说,每一行数据(每一个观测值)中的id都不同。我们可以用1比1合并,合并的效果如下:

Stata中的数据集采用了二维表的结构,其中行代表观测对象,列代表观测的特征指标。一行是同一个观测值的不同特征;一列是某一个观测特征下所有个体的对应观测值。 横向合并后的数据文件也应当遵循这一逻辑结构,因此在 图 2.6 的例子中,左边文件中id=1的个体(age=22)只能与右边文件中的1号个体关联起来(wt=130)。只有这样,才能保证在合并后的数据文件中“同一行仍然是同一个观测对象的不同特征”保持成立。
通过如下代码可以实现上述例子:
clear
input id age
1 22
2 56
5 17
end
list
save "masterfile.dta", replace
//
clear
input id wgt
1 130
2 180
4 110
end
list
save "usingfile.dta", replace
use "usingfile.dta", clear
merge 1:1 id using "masterfile.dta"
list
. clear
. input id age
id age
1. 1 22
2. 2 56
3. 5 17
4. end
. list
+----------+
| id age |
|----------|
1. | 1 22 |
2. | 2 56 |
3. | 5 17 |
+----------+
. save "masterfile.dta", replace
file masterfile.dta saved
. //
. clear
. input id wgt
id wgt
1. 1 130
2. 2 180
3. 4 110
4. end
. list
+----------+
| id wgt |
|----------|
1. | 1 130 |
2. | 2 180 |
3. | 4 110 |
+----------+
. save "usingfile.dta", replace
file usingfile.dta saved
.
. use "usingfile.dta", clear
. merge 1:1 id using "masterfile.dta"
Result Number of obs
-----------------------------------------
Not matched 2
from master 1 (_merge==1)
from using 1 (_merge==2)
Matched 2 (_merge==3)
-----------------------------------------
. list
+----------------------------------+
| id wgt age _merge |
|----------------------------------|
1. | 1 130 22 Matched (3) |
2. | 2 180 56 Matched (3) |
3. | 4 110 . Master only (1) |
4. | 5 . 17 Using only (2) |
+----------------------------------+
. 上面这段代码里有两条命令没有学习过,分别是input和list。其中input用于手动输入一些较为简单的数据,list则是将当前数据集内容打印在结果窗口中。可以通过help input与help list学习这两条命令的用法。
注意,在这个例子中,id变量是合并的关键词。 合并之后,系统自动生成了一个新的系统变量_merge,可以简写为_m,这个指标这里出现了三个取值:
| 取值 | 标签 | 含义 |
|---|---|---|
| 1 | master only (1) | 合并后的文件中,观测值仅在master数据中出现 |
| 2 | using only (2) | 合并后的文件中,观测值仅在using数据中出现 |
| 3 | matched (3) | 合并后的文件中,观测值在两个数据中均出现 |
多对一合并与一对一合并的主要区别是:合并的关键词(变量)是否能够唯一识别主文件和外部文件。 假如主数据(master)是关于某个地区(regione)内的一些人的数据,外部数据(using)是这个地区的特征,现在要将这两个文件进行横向合并:

两个数据中能够将两个文件联系起来的变量是“region”。在using文件中,region这个变量可以唯一识别其中的每一条数据,同一个region取值下只有一条数据。;但是在master数据中,region变量并不能唯一识别(id才可以),同一个region取值下可能有多条数据。因此我们采用多对一合并(m:1),这样可以将master文件中每一个region的取值对应的观测值都合并一条来自using文件中的变量x。
下面的代码实现了上述例子中的多对一合并
clear
input id region a
1 2 26
2 1 29
3 2 22
4 3 21
5 1 24
6 5 20
end
list
save "file1.dta", replace
clear
input region x
1 15
2 13
3 12
4 11
end
list
save "file2.dta", replace
use "file1.dta", clear
merge m:1 region using "file2.dta"
list
. clear
. input id region a
id region a
1. 1 2 26
2. 2 1 29
3. 3 2 22
4. 4 3 21
5. 5 1 24
6. 6 5 20
7. end
. list
+------------------+
| id region a |
|------------------|
1. | 1 2 26 |
2. | 2 1 29 |
3. | 3 2 22 |
4. | 4 3 21 |
5. | 5 1 24 |
|------------------|
6. | 6 5 20 |
+------------------+
. save "file1.dta", replace
file file1.dta saved
.
. clear
. input region x
region x
1. 1 15
2. 2 13
3. 3 12
4. 4 11
5. end
. list
+-------------+
| region x |
|-------------|
1. | 1 15 |
2. | 2 13 |
3. | 3 12 |
4. | 4 11 |
+-------------+
. save "file2.dta", replace
file file2.dta saved
.
. use "file1.dta", clear
. merge m:1 region using "file2.dta"
Result Number of obs
-----------------------------------------
Not matched 2
from master 1 (_merge==1)
from using 1 (_merge==2)
Matched 5 (_merge==3)
-----------------------------------------
. list
+-----------------------------------------+
| id region a x _merge |
|-----------------------------------------|
1. | 5 1 24 15 Matched (3) |
2. | 2 1 29 15 Matched (3) |
3. | 1 2 26 13 Matched (3) |
4. | 3 2 22 13 Matched (3) |
5. | 4 3 21 12 Matched (3) |
|-----------------------------------------|
6. | 6 5 20 . Master only (1) |
7. | . 4 . 11 Using only (2) |
+-----------------------------------------+
. 一对多合并与多对一合并是基本一样的,只是将master文件和using文件交换一下位置即可。

简单来说reshape命令的功能就是实现如下两种数据形式的互相转换

左边的数据格式称为“面板数据”(Panel Data),例如i代表股票代码,j代表年份,stub代表每年的累计收益率。而右侧是截面数据(cross-sectional data)id仍然是股票代码,stub1可以视股票2010年的收益率,subt2是股票2011年的收益率。 从面板数据转换为截面数据,通过reshape wide命令完成;从截面数据转换为面板数据,可以通过命令rehsape long来完成。下面的代码就实现了数据的长宽转换:
webuse reshape1, clear
describe
list
reshape long inc ue, i(id) j(year)
list, sep(3)
reshape wide inc ue, i(id) j(year)
list除了纵向合并(append)、横向合并(merge)、长宽转换(reshape)外,Stata中还有命令可以实现转置(transpose)、多对多合并(joinby)、两两交叉合并(cross),但大多数金融数据处理场景下并不需要它们,感兴趣的同学可以通过帮助文档查看学习(例如在Stata的命令窗口中键入help transpose)。
Stata的数据文件也可以导出为其他格式的文件,例如Excel文件、文本文件等。 对应于import delmited, import excel等导入文件,导出文件的命令为export excel和export delimited。请通过help export delimited和help export excel来学习这些命令的用法。下面展示的是一些简单用法(虽然简单,但也足够日常场景下的使用)
下面的代码可以先将stock_trade_data202101.dta的内容导出为excel文件:
use "stock_trade_data202101.dta", clear
destring 股票代码, replace
keep if 股票代码==1
export excel using "stock_trade_000001.xlsx", replace firstrow(variables)
export delimited using "stock_trade_000001.csv", replace delimiter(",")
export delimited using "stock_trade_000001.txt", replace delimiter(tab) use "stock_trade_data202101.dta", clear
destring 股票代码, replace
keep if 股票代码==2
export delimited using "stock_trade_000002.csv", replace delimiter(",")
export delimited using "stock_trade_000001.txt", replace delimiter(tab) 文件操作章节到此结束。在本章中,我们首先学习了如何将常见格式的数据文件(Excel文件或者csv文件、txt文件)等导入到Stata,并保存为Stata所特有的二进制格式数据文件(后缀名为.dta);然后介绍了对Stata中的文件进行简单的操作,包括横向拆分(通过命令drop或keep完成)、纵向拆分(通过命令drop if或keep if完成)、纵向合并(通过命令append完成)、横向合并(通过命令merge完成,并进一步分为一对一合并以及一对多合并)、长宽转换(通过命令reshape完成)。在本章的附录中,我们提供了本章中涉及的完整代码)。
1.导入数据文件index_trade_data202101.xlsx,保存为index_trade_data202101.dta,要求以第一行数据为变量名。
2.和drop命令相“反”的命令是keep,例如drop var1 是删除var1这个变量,相当于保留了除了var1之外所有的变量(对应的命令是keep var2 var3 var4,假设数据集中有4个变量var1 var2 var3 var4);再比如删除第一行数据的命令是drop if _n == 1,相当于保留了除了第一行之外的所有数据(对应的命令是keep if _n > 1)。请用keep命令改写如下代码(注意要保持命令的作用保持不变)。
sysuse auto, clear
drop if _n == 1
//
sysuse auto, clear
drop if _n == 2
//
sysuse auto, clear
drop if _n > (_N-5) 3.从stock_trade_data202101.dta中筛选出上海交易所的股票的股票代码、交易日期、收盘价和开盘价数据。 (提示:上海交易所和深圳交易所内的股票代码取值是有规律的,上交所的代码以6开头,深交所的代码以0开头,可以从对应的数值大小上区分两个市场的股票代码)
4.基于数据stock_trade_data202101.xlsx和index_trade_data202101.xlsx,从个股交易数据中提取简称为征和工业(代码:003033)的股票代码、股票简称、交易日期、收盘价和开盘价数据,保存为003033_trade_data202101.dta;
然后从指数交易数据中提取出上证180指数的指数名称、交易日期、总回报率数据,保存为Shangzheng180_trade_data202101.dta;
最后将003033_trade_data202101.dta和Shangzheng180_trade_data202101.dta文件进行横向合并,仅保留能够合并成功的观测值,保存为将最终的数据保存为trade_data_needed.dta。 (提示:[a]与python等编程语言类似,Stata同样区分字符和数值,字符需要用双引号引起来;[b]你可能需要用到修改变量名的命令:rename,它的基本语法是renmae oldname newname,你可以通过help rename来查看这个命令的使用方法)【补充提示:如果读入数据后发现股票代码、股票简称、指数代码、指数简称都是字符,可以考虑将股票代码和指数代码转换为数值型变量,然后依据数值型的代码变量写出逻辑表达式来提取特定的股票和指数。】
5.依据GDP1978-2022.xls数据,统计我国1978年至2022年间每一年的地级区划数量和地级市数量,文件保存为district1978to2022.dta,要求最终的数据文件: 1. 为long型数据(原始excel文件中为wide型数据); 1. 只包括3个变量——年份、地级区划数、地级市数; 1. 每一行中是的年份、地级区划的数量、地级市的数量; 1. 应当包括1978到2022年的所有数据。 (提示,你可以使用命令rename修改变量名)
// file: chap_file.do
// function: 演示文件操作
// author: 徐鑫 (XX)
// date-create: 2023-10-05
// date-modified: 2024-10-09
//
clear all
set more off
cd "C:/StataClass/chap_file"
// 导入Excel格式的外部数据文件
import excel using "./stock_trade_data202101.xlsx", clear
describe
import excel using "./stock_trade_data202101.xlsx", clear firstrow
import excel using "./stock_trade_data202101.xlsx", clear cellrange(A2)
//
// 导入csv格式的外部数据文件
import delimited using "./stock_trade_data202101-utf8.csv", clear delimiters(",") varname(1) encoding("utf8")
describe
// 保存dta格式数据到硬盘
import excel using "./stock_trade_data202101.xlsx", clear firstrow
save "./stock_trade_data202101.dta", replace
// 读入dta格式的数据
use "./stock_trade_data202101.dta", clear
// 读入系统自带数据
sysuse auto.dta, clear
// 读入网络数据
webuse nlswork, clear
use "https://gitee.com/znxkxx/stata2023/raw/master/week3/stock_trade_data202101.dta", clear
// 数据拆分
use "stock_trade_data202101.dta", clear
describe
drop 最高价 最低价 // 删除最高价和最低价两个变量
describe
keep 日期 股票代码 股票简称 开盘价 收盘价 //仅保留 若干感兴趣的变量
describe
use "stock_trade_data202101.dta", clear
destring 收盘价, replace
drop if 收盘价>50
use "stock_trade_data202101.dta", clear
drop if 股票简称 != "青岛啤酒" //删除股票简称不是"青岛啤酒"的观测值
save "青岛啤酒_交易数据.dta",replace
sysuse auto, clear
drop in 1
drop in 2
drop in 1/5
drop in -5/-1
drop if _n == 1
drop if _n == 2
drop if _n >= 1 & _n <= 5
drop if _n > (_N-5)
drop if _n >=-5 & _n <= -1
// 数据合并纵向合并
// 读取2021年1月的交易数据
use "stock_trade_data202101.dta", clear
keep if 日期 == "20210104"
save "stock_daily_return_20210104.dta", replace
// 读取2021年2月的交易数据
use "stock_trade_data202101.dta", clear
keep if 日期 == "20210105"
save "stock_daily_return_20210105.dta", replace
// 合并
use "stock_daily_return_20210104.dta", clear
append using "stock_daily_return_20210105.dta"
save "stock_daily_return_202101_04to05.dta", replace
// 数据横向合并
clear
input id age
1 22
2 56
5 17
end
list
save "masterfile.dta", replace
//
clear
input id wgt
1 130
2 180
4 110
end
list
save "usingfile.dta", replace
use "masterfile.dta", clear
list
merge 1:1 id using "usingfile.dta"
list
use "usingfile.dta", clear
list
merge 1:1 id using "masterfile.dta"
list
// 多对一、一对多横向合并
clear
input id region a
1 2 26
2 1 29
3 2 22
4 3 21
5 1 24
6 5 20
end
list
save "file1.dta", replace
clear
input region x
1 15
2 13
3 12
4 11
end
list
save "file2.dta", replace
use "file1.dta", clear
list
merge m:1 region using "file2.dta"
list
use "file2.dta", clear
list
merge 1:m region using "file1.dta"
list
// 数据长宽转换
webuse reshape1, clear
describe
list
reshape long inc ue, i(id) j(year)
list, sep(3)
reshape wide inc ue, i(id) j(year)
list
// 数据文件导出
use "stock_trade_data202101.dta", clear
destring 股票代码, replace
keep if 股票代码==1
export excel using "stock_trade_000001.xlsx", replace firstrow(variables)
export delimited using "stock_trade_000001.csv", replace delimiter(",")
export delimited using "stock_trade_000001.txt", replace delimiter(tab) 
C:/StataClass/week3\目录下。stock_trade_data202101.xlsx文件,另存为 CSV UTF-8 (Comma delimited)(*.csv)文件,文件名保存为stock_trade_data202101-utf8.csv。如果你用Notepad(记事本程序,Windows系统自带,Mac下是文本编辑器,类似)打开csv文件,可以发现每一个数据点之间有一个逗号用于分割数据。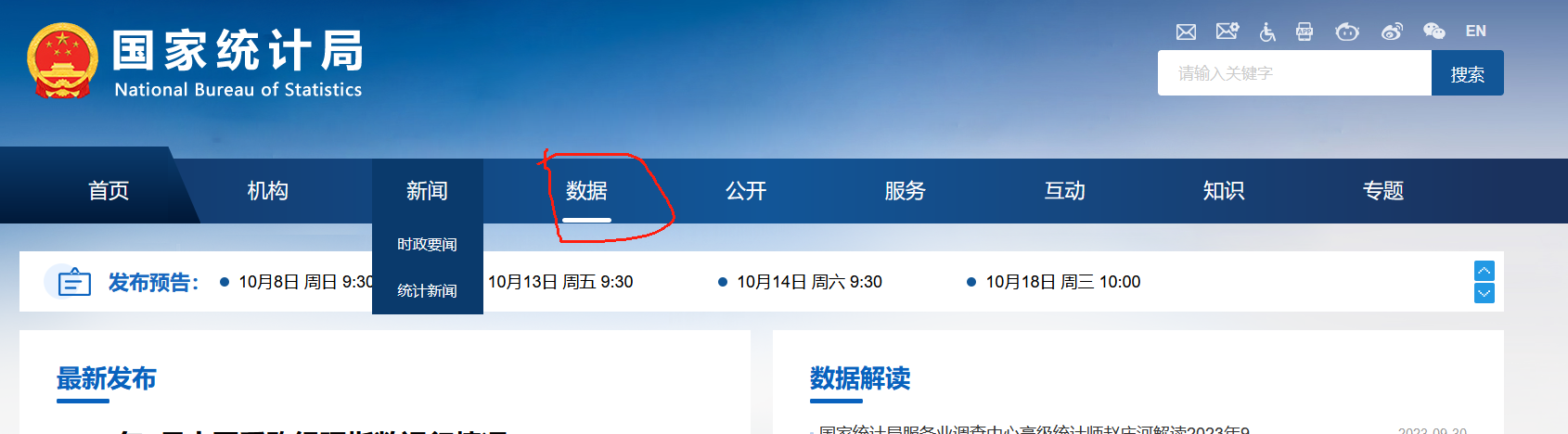
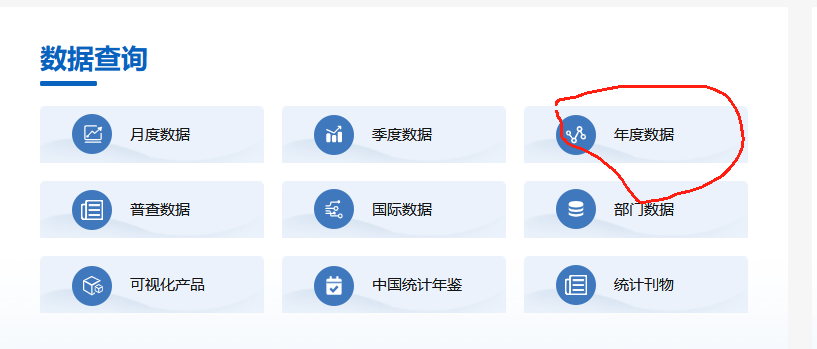
你可能会看到提示,网页证书过期的提醒,选择继续浏览即可,例如以下是我使用Edge浏览器看到的提醒(不同浏览器看到的界面大同小异):

注册,并在新页面中完成注册操作,后续数据下载需要登录账户。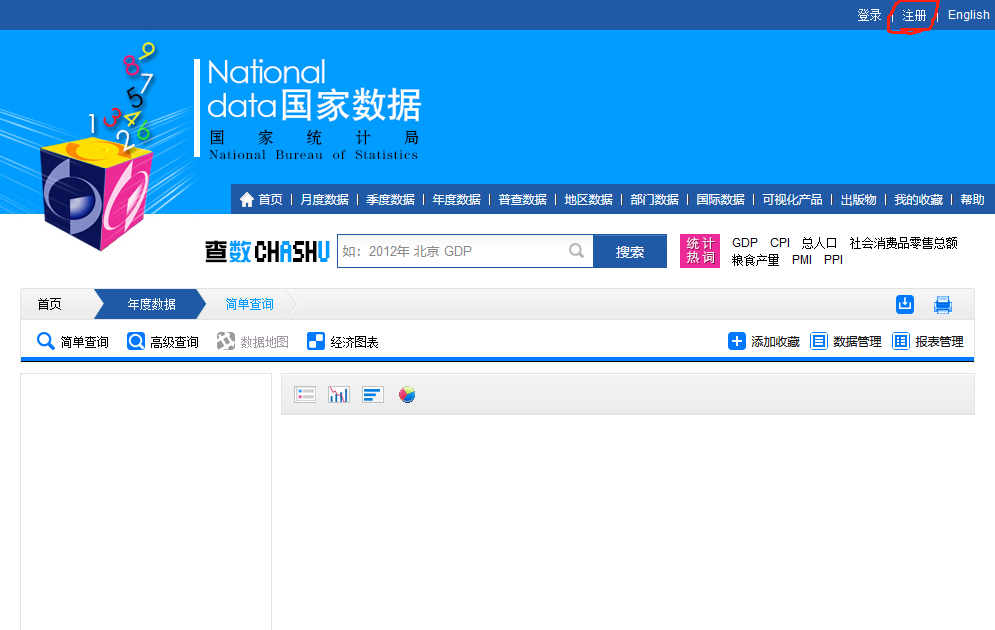
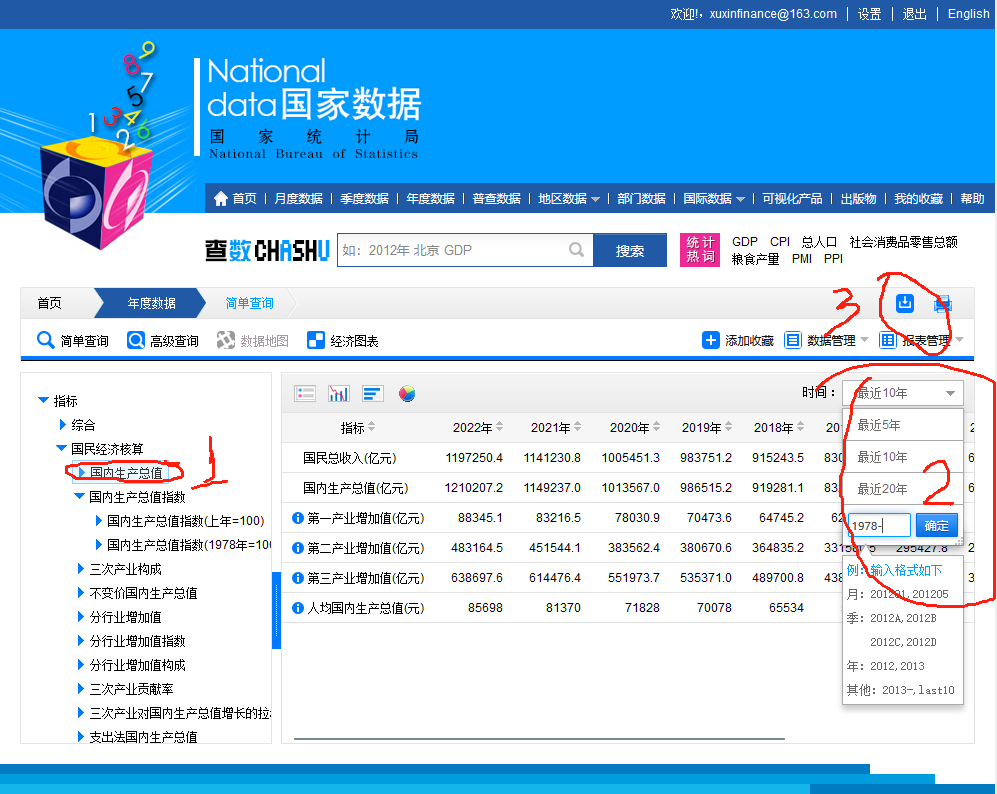
GDP1978-2022.xls和GDP1978-2022.csv(CSV格式的文件也可以在office中进行处理)