di _pi
di c(pi)
. di _pi
3.1415927
. di c(pi)
3.1415927
. 本章中,我们将会介绍函数(function)的用法。就数据处理的主题来讲,函数主要的用处是与generate、egen、replace等命令连用,生成变量或者改变变量的取值。当然,函数也可以用于数值或者字符的运算,通过display命令可以快速看到运算结果。
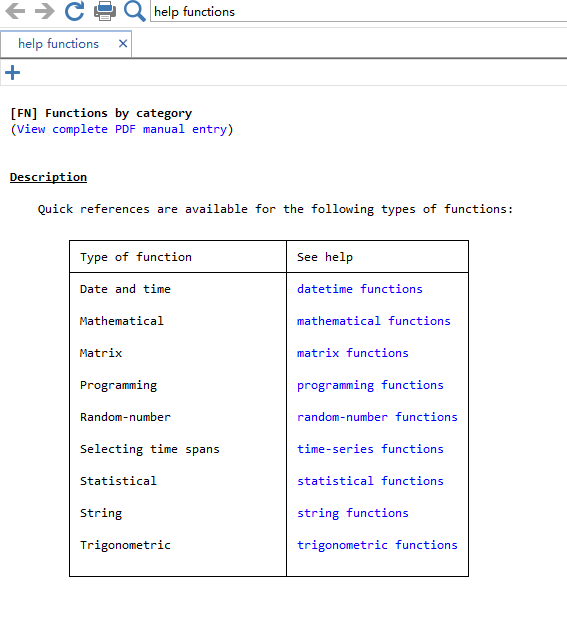
在Stata中通过输入命令help function可以打开函数概览页面,从中可以看出Stata中的函数可以分为:日期和时间函数、数学函数、矩阵函数、编程函数、随机数函数、时间序列函数、统计函数、字符串函数和三角函数等9种类型。通常来说,函数可以作用于数值、字符,更重要的是可以作用于变量,从而实现通过一些复杂的方法生成新的变量或者改变已有变量的取值。
需要注意的是,一个函数有参数(也可以称为自变量、输入值等),也会有返回值(也成为结果、输出值等),返回值就是将参数带入函数运算的结果。例如开平方根函数sqrt(4)=2这个运算,4就是函数sqrt( )的参数,2就是函数(根据参数运算后)的返回值。
上述第9种三角函数也属于数学函数。因此我们将函数共计分为8类。本章主要介绍:数学函数、字符函数和统计函数等。
完整的数学函数,可以通过help math_functions来系统学习,常见数学函数列示如下:
| 函数 | 含义 | 例子 |
|---|---|---|
| abs(x) | 绝对值 | abs(-9)=abs(9)=9 |
| comb(n,k) | 组合数 C_n^k | comb(10,2)=45 |
| exp(x) | 指数 | exp(0)=1 |
| ceil(x) | 向上取整 | ceil(3.2)=4; ceil(3.9)=4 |
| floor(x) | 向下取整 | floor(3.2)=3; floor(3.9)=3 |
| int(x) | 提取整数部分 | int(3.2)=3 int(3.9)=3 |
| ln(x), log(x) | 自然对数 | ln(1)=0, ln(e)=1 |
| log10(x) | 以10为底的对数 | ln(10)=1 |
| max(x1,x2,…,xn) | 最大值 | max(2,3,4)=4, max(.,3,10)=. |
| min(x1,x2,…,xn) | 最小值 | min(2,3,4)=2, min(.,3,10)=3 |
| mod(x,y) | 余数 | mod(3,2)=1; mod(x,0)=. |
| round(x[,y]) | 舍入 | round(3.45)=3, round(3.45, 0.1)=3.5 |
| sqrt(x) | 开方 | sqrt(4)=2, sqrt(9)=3 |
| sign(x) | 符号 | sign(-101)=-1, sign(234)=+1, sign(0)=0 |
| sin(x) | 正弦函数,弧度 | |
| cox(x) | 余弦函数,弧度 | |
| tan(x) | 正切函数,弧度 | |
| cot(x) | 余切函数,弧度 |
Stata中还有一些系统常量,例如我们之前介绍的_n为当前观测值的序号;_N为一共有多少观测值。_pi代表圆周率,也可以用c(pi)来表示;另外可以通过命令creturn list查看Stata中所有的常量。
di _pi
di c(pi)
. di _pi
3.1415927
. di c(pi)
3.1415927
. 数学函数可以直接对数据进行运算,也可以针对变量进行运算。
di sqrt(4)
di sqrt(6+3)
di abs(-100)
di exp(1)
di ln(exp(2))
di _pi
di cos(_pi)
clear
set obs 5
gen x = _n
gen y1 = exp(x)
gen y2 = ln(x)
gen y3 = sin(exp(x))+cos(ln(x))
gen y4 = sin(y1)+cos(y2)
list
. di sqrt(4)
2
. di sqrt(6+3)
3
. di abs(-100)
100
. di exp(1)
2.7182818
. di ln(exp(2))
2
. di _pi
3.1415927
. di cos(_pi)
-1
.
. clear
. set obs 5
Number of observations (_N) was 0, now 5.
. gen x = _n
. gen y1 = exp(x)
. gen y2 = ln(x)
. gen y3 = sin(exp(x))+cos(ln(x))
. gen y4 = sin(y1)+cos(y2)
. list
+-------------------------------------------------+
| x y1 y2 y3 y4 |
|-------------------------------------------------|
1. | 1 2.718282 0 1.410781 1.410781 |
2. | 2 7.389056 .6931472 1.663094 1.663094 |
3. | 3 20.08554 1.098612 1.399303 1.399303 |
4. | 4 54.59815 1.386294 -.745311 -.7453104 |
5. | 5 148.4132 1.609438 -.7263234 -.7263257 |
+-------------------------------------------------+
. 可以用于取整的函数是int(),用于舍入的函数是round()(这里的舍入并非严格按照我们熟悉的四舍五入规则,主要原因在于Stata中的数据精度问题,具体可以参见round()函数的帮助文档,以及对Stata精度的进一步说明help precision,但基本可以按照四舍五入理解。)
// 取整
di int(3.49)
di int(3.51)
di int(-3.49)
di int(-3.51)
di ceil(3)
di ceil(3.99)
di ceil(3.01)
di floor(3)
di floor(3.99)
di floor(3.01)
// 舍入
di round(3.49)
di round(3.51)
di round(-3.49)
di round(-3.51)
// 指定舍入精度
di round(3.345,0.1)
di round(3.345,.1)
di round(-3.345,0.01)
di round(-333.345,10)
// 计算余数
di mod(5,2) //计算5/2的余数字
di mod(4,2)
// 变量层面的操作
sysuse auto, clear
gen nprice = price/10000 // 将价格变成以万为单位
gen nprice1 = round(nprice,0.01) // 舍入到小数点后2位(百分位)
list nprice* in 1/6 //列出以nprice开头的所有变量前6行
. // 取整
. di int(3.49)
3
. di int(3.51)
3
. di int(-3.49)
-3
. di int(-3.51)
-3
.
. di ceil(3)
3
. di ceil(3.99)
4
. di ceil(3.01)
4
.
. di floor(3)
3
. di floor(3.99)
3
. di floor(3.01)
3
.
. // 舍入
. di round(3.49)
3
. di round(3.51)
4
. di round(-3.49)
-3
. di round(-3.51)
-4
. // 指定舍入精度
. di round(3.345,0.1)
3.3
. di round(3.345,.1)
3.3
. di round(-3.345,0.01)
-3.34
. di round(-333.345,10)
-330
.
. // 计算余数
. di mod(5,2) //计算5/2的余数字
1
. di mod(4,2)
0
.
. // 变量层面的操作
. sysuse auto, clear
(1978 automobile data)
. gen nprice = price/10000 // 将价格变成以万为单位
. gen nprice1 = round(nprice,0.01) // 舍入到小数点后2位(百分位)
. list nprice* in 1/6 //列出以nprice开头的所有变量前6行
+------------------+
| nprice nprice1 |
|------------------|
1. | .4099 .41 |
2. | .4749 .47 |
3. | .3799 .38 |
4. | .4816 .48 |
5. | .7827 .78 |
|------------------|
6. | .5788 .58 |
+------------------+
. 在上面的代码list nprice*中,*是通配符,含义是任意长度的内容,你可以尝试如下代码体会通配符的用法。
list np* in 1/6 //结果窗口显示所有以np开头的变量前6行的数据
list nprice1* in 1/6 //结果窗口显示所有以nprice1开头的变量前6行的数据首先请大家回忆一下,我们日常中是如何来表示日期、年月的?
日期:
年月:
通常来说,这些表示方式如果出现在Stata中,只能是以字符型数据出现,但是字符型数据不太方便进行甲减等数值处理。
例如某一个日期加上一个正整数(即一个日期之后的那一天)仍然是一个日期;两个日期相减对应的是两个日期之间相差几天。年月也有类似的处理。
Stata中的处理方式是将所有的日期(包括时间)都映射到整数上。
日期函数,广义上来说是日期时间函数,在Stata命令行中键入help function后打开的函数列表中,会看到九大类函数中日期时间函数(datetime function)。点击”datetime function”会打开新的窗口,弹出所有的日期时间函数。
所谓日期,就是指的是”2022-12-01”、或者”2022年12月31日”这样的表达式或者变量(的取值)。在Stata中日期是以整数来表示。具体来说,Stata以1960年1月1日为第0天,比这一天更早的日期以负整数表示,例如1959年12月31日为-1;比这一天更晚的日期以正整数来表示,例如1960年1月2日为1。
disp mdy(1,1,1960)
disp mdy(12,31,1959)
disp mdy(1,2,1960)在上面的例子中 mdy()是一个函数,它有三个参数,依此是月份、日期和年份,函数的输出值是日期,但是从上面的结果可以看出这里直接输出的是整数的数字。通过help mdy()可以打开其帮助文档的说明:
.png)
我们可以通过改变结果的显示格式将日期显示为我们日常熟悉的“年-月-日”格式:
disp %tdCY-N-D mdy(1,1,1960)这里的%tdCY-N-D 是一种显示格式,我们在之前讲过format明令时提到,和%f、%g等类似,%td也是一种显示格式,它代表日期显示格式;后面的CY-N-D中,C代表Century(01-99),Y代表年份(00-99),N1代表数字表示的月份(01-12),D代表日期(01-31);短线“-”也会直接显示为短线。当然关于日期时间的显示格式还有很多种,例如你可以尝试下面的代码,查看不同的日期显示样式,甚至可以只显示日期中的年、月而不显示日期的部分。
disp %tdCY_N_D mdy(1,1,1960)
disp %tdCY-M-D mdy(1,1,1960)
disp %tdCY-N mdy(1,1,1960) //可以只展示日期中的年月部分具体可以通过命令help datetime_display_formats查看。
除了从年、月、日的数值来生成日期之外,还可以将已有的日期字符(如“2021-12-11”)转换为日期。
disp date("2024-11-06","YMD") // 第二个参数指定了第一个字符串中年月日的顺序
disp date("2024-11-06","YDM")
disp date("11-06-2024","MDY")
disp %tdCY-N-D date("2024-11-06","YMD")
disp %tdCY-M-D date("2024-11-06","YMD")从日期型数值可以计算对应的年份、月份、周、日和日内星期几,对应的函数分别是:year(), month(), week()2, day()和dow()。
disp %tdCY-N-D date("2021-12-11","YMD")
disp year(date("2021-12-11","YMD"))
disp month(date("2021-12-11","YMD"))
disp week(date("2021-12-11","YMD"))
disp day(date("2021-12-11","YMD"))
disp dow(date("2021-12-11","YMD"))
. disp %tdCY-N-D date("2021-12-11","YMD")
2021-12-11
. disp year(date("2021-12-11","YMD"))
2021
. disp month(date("2021-12-11","YMD"))
12
. disp week(date("2021-12-11","YMD"))
50
. disp day(date("2021-12-11","YMD"))
11
. disp dow(date("2021-12-11","YMD"))
6
. 上述函数可以分别通过help year(), help month()…等查看帮助文档。他们的参数都是一个日期(也就是一个整数)。
除了日期之外,还有一些数据可能是月度频率,Stata引入了”年月”值的概念,将每一个年月对应到一个整数,其中1960年1月对应整数0,1960年2月对应整数1,1959年12月对应-1。
di ym(1960,1)
di ym(2022,12)
di %tmCY-N ym(2022,12)
di %tmCY-N-D ym(2022,12)
. di ym(1960,1)
0
. di ym(2022,12)
755
. di %tmCY-N ym(2022,12)
2022-12
. di %tmCY-N-D ym(2022,12)
2022-12-01
. 可以看到函数ym()可以实现将年份、月份转换为年月值,它的参数有两个,分别是年份和月份,可以通过help ym()来查看该函数的帮助文档。另外上面最后一行代码的例子可以看出:尽管年月没有日期,如果显示格式中要求显示日期,Stata会显示对应年月的第一天。
另外%tmCY-N是年月数值的显示格式,其中%tm和日期中的%td对应。CY-N
上面我们介绍了两种显示格式:%td和tm,它们对应于日度和月度频率的数据。Stata通过将“日期”和“年月”映射到整数集(其他软件例如python也是如此),实现了日期数据的处理。但由于“日期”和“年月”都被映射到了同一个整数集,导致同一个整数既可以理解为日期也可以理解为年月,例如120既可以是相对于基准日期(1960-01-01)过去了120天,也可以理解为是相对于基准年月(1960-01)过去了120个月。因此必须要通过格式明确究竟是按照日期理解(%td)还是按照“年月”理解(%tm)。
观察如下代码,体会它们的差异:
di %tdCY-N-D 120
di %tmCY-N 120
di %tmCY-N ym(2022,12)
di %tdCY-N ym(2022,12)在处理日期时,一定要注意它们的频率。
dofm()函数则提供了从年月得到日期的功能,具体来说给出的是对应年月的第一天:
di dofm(ym(2022,12))
di %tdCY-N-D dofm(ym(2022,12))
. di dofm(ym(2022,12))
22980
. di %tdCY-N-D dofm(ym(2022,12))
2022-12-01
. 如果给定年月,如2022年12月,如何得到前一个月的最后一天的日期值?(课后习题中的)
类似“年月”,如果你的数据是季度频率,Stata中也有“年季”来处理。具体来说,Stata将“1960年的第1季度”作为第0个季度,所有的“年季”都用相对于基准过去的季度数量。“年季”的对应格式是%tq,函数yq()可以根据年份和季度生成“年季”值,函数dofq()则给出了“年季”所对应的日期(同样是对应季度的第一天)。下面的代码展示了相关函数的用法
di yq(2022,4)
di %tqCY-q yq(2022,4)
di %tdCY-N-D dofq(yq(2022,4))
. di yq(2022,4)
251
. di %tqCY-q yq(2022,4)
2022-4
. di %tdCY-N-D dofq(yq(2022,4))
2022-10-01
. 上述日期时间函数同样可以作用于变量,而且作用于变量是数据分析过程中更加常见的过程。
我们通过如下命令分别生成两个日期文档和年月文件:
cd C:\StataClass\chap_function
clear
input str10 date
"2021-01-01"
"2021-01-02"
"2021-01-03"
"2021-01-04"
"2021-01-05"
"2021-01-06"
"2021-01-07"
"2021-01-08"
"2021-01-09"
"2021-01-10"
"2021-01-11"
"2021-01-12"
"2021-01-13"
"2021-01-14"
"2021-01-15"
"2021-01-16"
"2021-01-17"
"2021-01-18"
"2021-01-19"
"2021-01-20"
"2021-01-21"
"2021-01-22"
"2021-01-23"
"2021-01-24"
"2021-01-25"
"2021-01-26"
"2021-01-27"
"2021-01-28"
"2021-01-29"
"2021-01-30"
"2021-01-31"
end
save "./date.dta", replace
. cd C:\StataClass\chap_function
C:\StataClass\chap_function
. clear
. input str10 date
date
1. "2021-01-01"
2. "2021-01-02"
3. "2021-01-03"
4. "2021-01-04"
5. "2021-01-05"
6. "2021-01-06"
7. "2021-01-07"
8. "2021-01-08"
9. "2021-01-09"
10. "2021-01-10"
11. "2021-01-11"
12. "2021-01-12"
13. "2021-01-13"
14. "2021-01-14"
15. "2021-01-15"
16. "2021-01-16"
17. "2021-01-17"
18. "2021-01-18"
19. "2021-01-19"
20. "2021-01-20"
21. "2021-01-21"
22. "2021-01-22"
23. "2021-01-23"
24. "2021-01-24"
25. "2021-01-25"
26. "2021-01-26"
27. "2021-01-27"
28. "2021-01-28"
29. "2021-01-29"
30. "2021-01-30"
31. "2021-01-31"
32. end
. save "./date.dta", replace
file ./date.dta saved
. 上述代码生成了数据文件date.dta,其中包含一个字符型变量date。下面代码展示了日期、年月函数的用法:
use "./date.dta", clear
// 通过date()函数将字符串日期转换为数值型日期:
gen temp = date(date,"YMD")
format temp %tdCY-N-D
// 通过year()函数、month()函数和day()函数得到年、月、日
gen year = year(temp)
gen month = month(temp)
gen day = day(temp)
// 利用mdy()函数从年月日反得到日期
gen date1 = mdy(month,day,year)
gen ym = ym(year,month)
gen ym1 = ym(year(temp),month(temp))
format ym %tmCY-N
format ym1 %tmCY-N
// 通过dofm()反推日期
gen date_ym = dofm(ym)
// 通过quarter()函数得到日期的季度
gen quarter = quarter(temp)
// 通过yq函数得到年季
gen yq = yq(year,quarter)
format yq %tqCY-q
// 通过dofq()反推日期
gen date_yq = dofq(yq)
// 利用取子串函数也可以从字符日期中得到年、月并进一步生成年-月指标
gen ym2 = ym(real(substr(date,1,4)),real(substr(date,6,2)))
gen date2 = dofm(ym)
format date2 %tdCY-N-D
list
. use "./date.dta", clear
. // 通过date()函数将字符串日期转换为数值型日期:
. gen temp = date(date,"YMD")
. format temp %tdCY-N-D
. // 通过year()函数、month()函数和day()函数得到年、月、日
. gen year = year(temp)
. gen month = month(temp)
. gen day = day(temp)
. // 利用mdy()函数从年月日反得到日期
. gen date1 = mdy(month,day,year)
. gen ym = ym(year,month)
. gen ym1 = ym(year(temp),month(temp))
. format ym %tmCY-N
. format ym1 %tmCY-N
. // 通过dofm()反推日期
. gen date_ym = dofm(ym)
. // 通过quarter()函数得到日期的季度
. gen quarter = quarter(temp)
. // 通过yq函数得到年季
. gen yq = yq(year,quarter)
. format yq %tqCY-q
. // 通过dofq()反推日期
. gen date_yq = dofq(yq)
.
. // 利用取子串函数也可以从字符日期中得到年、月并进一步生成年-月指标
. gen ym2 = ym(real(substr(date,1,4)),real(substr(date,6,2)))
. gen date2 = dofm(ym)
. format date2 %tdCY-N-D
. list
+-------------------------------------------------------------------+
1. | date | temp | year | month | day | date1 | ym |
| 2021-01-01 | 2021-01-01 | 2021 | 1 | 1 | 22281 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
2. | date | temp | year | month | day | date1 | ym |
| 2021-01-02 | 2021-01-02 | 2021 | 1 | 2 | 22282 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
3. | date | temp | year | month | day | date1 | ym |
| 2021-01-03 | 2021-01-03 | 2021 | 1 | 3 | 22283 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
4. | date | temp | year | month | day | date1 | ym |
| 2021-01-04 | 2021-01-04 | 2021 | 1 | 4 | 22284 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
5. | date | temp | year | month | day | date1 | ym |
| 2021-01-05 | 2021-01-05 | 2021 | 1 | 5 | 22285 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
6. | date | temp | year | month | day | date1 | ym |
| 2021-01-06 | 2021-01-06 | 2021 | 1 | 6 | 22286 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
7. | date | temp | year | month | day | date1 | ym |
| 2021-01-07 | 2021-01-07 | 2021 | 1 | 7 | 22287 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
8. | date | temp | year | month | day | date1 | ym |
| 2021-01-08 | 2021-01-08 | 2021 | 1 | 8 | 22288 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
9. | date | temp | year | month | day | date1 | ym |
| 2021-01-09 | 2021-01-09 | 2021 | 1 | 9 | 22289 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
10. | date | temp | year | month | day | date1 | ym |
| 2021-01-10 | 2021-01-10 | 2021 | 1 | 10 | 22290 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
11. | date | temp | year | month | day | date1 | ym |
| 2021-01-11 | 2021-01-11 | 2021 | 1 | 11 | 22291 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
12. | date | temp | year | month | day | date1 | ym |
| 2021-01-12 | 2021-01-12 | 2021 | 1 | 12 | 22292 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
13. | date | temp | year | month | day | date1 | ym |
| 2021-01-13 | 2021-01-13 | 2021 | 1 | 13 | 22293 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
14. | date | temp | year | month | day | date1 | ym |
| 2021-01-14 | 2021-01-14 | 2021 | 1 | 14 | 22294 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
15. | date | temp | year | month | day | date1 | ym |
| 2021-01-15 | 2021-01-15 | 2021 | 1 | 15 | 22295 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
16. | date | temp | year | month | day | date1 | ym |
| 2021-01-16 | 2021-01-16 | 2021 | 1 | 16 | 22296 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
17. | date | temp | year | month | day | date1 | ym |
| 2021-01-17 | 2021-01-17 | 2021 | 1 | 17 | 22297 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
18. | date | temp | year | month | day | date1 | ym |
| 2021-01-18 | 2021-01-18 | 2021 | 1 | 18 | 22298 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
19. | date | temp | year | month | day | date1 | ym |
| 2021-01-19 | 2021-01-19 | 2021 | 1 | 19 | 22299 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
20. | date | temp | year | month | day | date1 | ym |
| 2021-01-20 | 2021-01-20 | 2021 | 1 | 20 | 22300 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
21. | date | temp | year | month | day | date1 | ym |
| 2021-01-21 | 2021-01-21 | 2021 | 1 | 21 | 22301 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
22. | date | temp | year | month | day | date1 | ym |
| 2021-01-22 | 2021-01-22 | 2021 | 1 | 22 | 22302 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
23. | date | temp | year | month | day | date1 | ym |
| 2021-01-23 | 2021-01-23 | 2021 | 1 | 23 | 22303 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
24. | date | temp | year | month | day | date1 | ym |
| 2021-01-24 | 2021-01-24 | 2021 | 1 | 24 | 22304 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
25. | date | temp | year | month | day | date1 | ym |
| 2021-01-25 | 2021-01-25 | 2021 | 1 | 25 | 22305 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
26. | date | temp | year | month | day | date1 | ym |
| 2021-01-26 | 2021-01-26 | 2021 | 1 | 26 | 22306 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
27. | date | temp | year | month | day | date1 | ym |
| 2021-01-27 | 2021-01-27 | 2021 | 1 | 27 | 22307 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
28. | date | temp | year | month | day | date1 | ym |
| 2021-01-28 | 2021-01-28 | 2021 | 1 | 28 | 22308 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
29. | date | temp | year | month | day | date1 | ym |
| 2021-01-29 | 2021-01-29 | 2021 | 1 | 29 | 22309 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
30. | date | temp | year | month | day | date1 | ym |
| 2021-01-30 | 2021-01-30 | 2021 | 1 | 30 | 22310 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
+-------------------------------------------------------------------+
31. | date | temp | year | month | day | date1 | ym |
| 2021-01-31 | 2021-01-31 | 2021 | 1 | 31 | 22311 | 2021-01 |
|-------------------------------------------------------------------|
| ym1 | date_ym | quarter | yq | date_yq | ym2 | date2 |
| 2021-01 | 22281 | 1 | 2021-1 | 22281 | 732 | 2021-01-01 |
+-------------------------------------------------------------------+
. 字符串函数是指处理字符串变量或者字符串常量的函数。字符串的函数有很多,日常工作学习中常用到的函数包括如下几类:
由于在不同编码之下,字符在计算机中所占的存储空间是不一样的,因此本章中介绍的大多数字符串相关的函数但多有两个版本:针对ASCII字符的函数和针对utf8函数的版本,后者一般是在前者的函数名称前增加一个u。
ASCII编码和utf8编码都是计算机中的字符编码标准,类似的还有GB2312,GBK等,它们会采用不同的方案,将计算机上的二进制数字转换为人能够识别的字母、文字。你可能遇到过乱码或者方框等显示不出来字符的情况,这些都和字符的编码有关。关于编码的介绍,可以查看下面的科普视频:
计算字符串长度的函数是 strlen()和ustrlen(),函数strlen(string)的功能是,对于给定的字符串string,返回该字符串中包含字符的个数。需要注意的是,strlen()这个函数的是针对ASCII编码,共计有128个常见的英文字符和其他符号,每个字符由一个字节(byte,相当于8位二级制数 8 bits)表示 ,strlen()实际上返回的是字符对应的字节数;例如strlen("abc")的返回值是3、strlen("ab")的返回值是2。一个较为特殊的例子是空格和空串,空格是字符的一种,而空串是没有任何内容的字符串,因此一个空格的长度是1,而空串的长度是0。
di strlen("abc")
di strlen("ab")
di strlen(" ")
di strlen(" ")
di strlen("")
. di strlen("abc")
3
. di strlen("ab")
2
. di strlen(" ")
1
. di strlen(" ")
2
. di strlen("")
0
. 在Stata 14以及后续的版本中,Stata引入了utf8编码,这克服了ASICC只能表示有限数量的字符、对非英文支持不好的缺点。为了表示更多的字符,每个字符需要占用更多的空间,一中文汉字为例,一个汉字“中”需要3个字节长度,因此strlen("我")的返回值是3、strlen("我爱学习")的返回值是12。 为了计算utf8编码 下字符串的长度(即字符的个数),需要使用函数ustrlen()。
di strlen("我")
di ustrlen("我")
. di strlen("我")
3
. di ustrlen("我")
1
. 计算字符串的长度当然可以用于变量上,示例如下:
clear
set obs 3
gen x = "广东省"
replace x = "广西省"
replace x = "内蒙古自治区"
generate len_x = strlen(x)
gen len_x1 = ustrlen(x) // utf8函数更加符合直觉
. clear
. set obs 3
Number of observations (_N) was 0, now 3.
. gen x = "广东省"
. replace x = "广西省"
(3 real changes made)
. replace x = "内蒙古自治区"
variable x was str9 now str18
(3 real changes made)
.
. generate len_x = strlen(x)
. gen len_x1 = ustrlen(x) // utf8函数更加符合直觉
. 子串是指某个字符串中截取到的一段连续内容,可以视为是该字符串中的子集。
提取子串的函数是substr(s, n1, n2),含义是从字符串s的第n1个字符开始,提取长度为n2的子串。例如substr("abcde",2,3)的返回值是"bcd"。这里第一个参数n1是指示子串开始的位置,在原字符串s中,第一个字符"a"的位置是1,第二个字符"b"的位置是2。参数n1的取值也可以是负整数,这代表子串的起始位置是从后往前倒数。与函数strlen()一样的原因,substr()函数在处理非ASCII字符时存在不变,应当使用函数usubstr()。
di substr("abcde", 2, 3)
di substr("abcde", -2,1)
di substr("abcde", 2, .)
di substr("我爱中国",2,3)
di substr("我爱中国",4,6)
di usubstr("我爱中国",2,2)
clear
set obs 2
gen x = "广东省广州市"
replace x= "广东省深圳市" in 2
gen prov = usubstr(x,1,3)
gen city = usubstr(x,4,3)
. di substr("abcde", 2, 3)
bcd
. di substr("abcde", -2,1)
d
. di substr("abcde", 2, .)
bcde
. di substr("我爱中国",2,3)
\x88\x91\xe7
. di substr("我爱中国",4,6)
爱中
. di usubstr("我爱中国",2,2)
爱中
.
. clear
. set obs 2
Number of observations (_N) was 0, now 2.
. gen x = "广东省广州市"
. replace x= "广东省深圳市" in 2
(1 real change made)
. gen prov = usubstr(x,1,3)
. gen city = usubstr(x,4,3)
. 定位子串的函数是strpos(s1,s2)和ustrpos(s1,s2),分别对应ASCII编码和utf8编码下的字符串。功能是计算子串s2出现在字符串s1中的位置(即从第几个字符开始),返回值是非负整数。如果s2在s1中有多次出现,则返回第一个符合条件的字串的位置。例如 strpos("this","is")的返回值是3,strpos("apple","p")的返回值是2;当s2不在s1中时函数的返回值为0,例如strpos("this", "at")的返回值是0。ustrpos(s1,s2)适用于utf8编码(例如中文等非英文字符)的情况。
di strpos("this","is")
di strpos("this","it")
di ustrpos("我爱中国", "爱")
di strpos("我爱中国","爱")
clear
set obs 3
gen x = "广东省广州市"
replace x= "广东省深圳市" in 2
replace x = "内蒙古自治区巴彦淖尔市" in 3
list
gen prov = usubstr(x,1,3)
gen city = usubstr(x,4,3)
list
gen prov_pos = ustrpos(x,"省")
list
replace prov_pos = ustrpos(x,"自治区")+2 if prov_pos == 0
list
gen prov1 = usubstr(x,1,prov_pos)
gen city1 = usubstr(x,prov_pos+1,.)
. di strpos("this","is")
3
. di strpos("this","it")
0
. di ustrpos("我爱中国", "爱")
2
. di strpos("我爱中国","爱")
4
.
. clear
. set obs 3
Number of observations (_N) was 0, now 3.
. gen x = "广东省广州市"
. replace x= "广东省深圳市" in 2
(1 real change made)
. replace x = "内蒙古自治区巴彦淖尔市" in 3
variable x was str18 now str33
(1 real change made)
. list
+------------------------+
| x |
|------------------------|
1. | 广东省广州市 |
2. | 广东省深圳市 |
3. | 内蒙古自治区巴彦淖尔市 |
+------------------------+
. gen prov = usubstr(x,1,3)
. gen city = usubstr(x,4,3)
. list
+------------------------------------------+
| x prov city |
|------------------------------------------|
1. | 广东省广州市 广东省 广州市 |
2. | 广东省深圳市 广东省 深圳市 |
3. | 内蒙古自治区巴彦淖尔市 内蒙古 自治区 |
+------------------------------------------+
. gen prov_pos = ustrpos(x,"省")
. list
+-----------------------------------------------------+
| x prov city prov_pos |
|-----------------------------------------------------|
1. | 广东省广州市 广东省 广州市 3 |
2. | 广东省深圳市 广东省 深圳市 3 |
3. | 内蒙古自治区巴彦淖尔市 内蒙古 自治区 0 |
+-----------------------------------------------------+
. replace prov_pos = ustrpos(x,"自治区")+2 if prov_pos == 0
(1 real change made)
. list
+-----------------------------------------------------+
| x prov city prov_pos |
|-----------------------------------------------------|
1. | 广东省广州市 广东省 广州市 3 |
2. | 广东省深圳市 广东省 深圳市 3 |
3. | 内蒙古自治区巴彦淖尔市 内蒙古 自治区 6 |
+-----------------------------------------------------+
.
. gen prov1 = usubstr(x,1,prov_pos)
. gen city1 = usubstr(x,prov_pos+1,.)
. 子串替换的函数是subinstr(s1,s2,s3,n) 和usubinstr(s1,s2,s3,n)。功能是将字符串s1中的某个(些)字串s2,替换为字符串s3。最后一个参数n决定了替换字串的数量,如果字符串s2在s1中出现多次,则替换前n次出现的子串s2,当参数n的取值为missing value (.)的时候代表把s1中所有的s2字串都进行替换。与前面的函数类似,usubinstr(s1,s2,s3,n)用于处理utf8编码下的字符串。
下面的例子展示了利用子串替换函数实现删除字符的用法(即用空串替换目标子串):
disp subinstr("this is the day","is","X",1)
disp subinstr("this is the day","is","X",2)
disp subinstr("this is this","is","X",.)
clear
set obs 3
gen x = "广东省广州市"
replace x= "广东省深圳市" in 2
replace x = "内蒙古自治区巴彦淖尔市" in 3
gen prov_pos = ustrpos(x,"省")
replace prov_pos = ustrpos(x,"自治区")+2 if prov_pos == 0
gen prov1 = usubstr(x,1,prov_pos)
gen city1 = usubstr(x,prov_pos+1,.)
replace prov1 = usubinstr(prov1,"省","",.)
replace prov1 = usubinstr(prov1,"自治区","",.)
replace city1 = usubinstr(city1,"市","",.)
. disp subinstr("this is the day","is","X",1)
thX is the day
. disp subinstr("this is the day","is","X",2)
thX X the day
. disp subinstr("this is this","is","X",.)
thX X thX
.
. clear
. set obs 3
Number of observations (_N) was 0, now 3.
. gen x = "广东省广州市"
. replace x= "广东省深圳市" in 2
(1 real change made)
. replace x = "内蒙古自治区巴彦淖尔市" in 3
variable x was str18 now str33
(1 real change made)
. gen prov_pos = ustrpos(x,"省")
. replace prov_pos = ustrpos(x,"自治区")+2 if prov_pos == 0
(1 real change made)
. gen prov1 = usubstr(x,1,prov_pos)
. gen city1 = usubstr(x,prov_pos+1,.)
.
. replace prov1 = usubinstr(prov1,"省","",.)
(2 real changes made)
. replace prov1 = usubinstr(prov1,"自治区","",.)
(1 real change made)
. replace city1 = usubinstr(city1,"市","",.)
(3 real changes made)
. 我们可以通过split命令将一列字符串变量拆分成多个变量,split的语法结构如下:

下面的两个例子,分别实现了从日期“2022-10-01”中分别提取年、月、日和从邮箱地址中提取姓名。
clear all
set obs 5
generate day = _n
tostring day, replace format(%02.0f)
gen date = "2022-10-"+day
drop day
list
split date, parse("-")
list
clear
input str20 email
"张三@gdufe.edu.cn"
"李四@gdufe.edu"
"王五@gdufe"
end
list
split email, parse("@")
list
drop email1 email2
split email, parse(".") generate(web_addr)
list
. clear all
. set obs 5
Number of observations (_N) was 0, now 5.
. generate day = _n
. tostring day, replace format(%02.0f)
day was float now str2
. gen date = "2022-10-"+day
. drop day
. list
+------------+
| date |
|------------|
1. | 2022-10-01 |
2. | 2022-10-02 |
3. | 2022-10-03 |
4. | 2022-10-04 |
5. | 2022-10-05 |
+------------+
. split date, parse("-")
variables created as string:
date1 date2 date3
. list
+------------------------------------+
| date date1 date2 date3 |
|------------------------------------|
1. | 2022-10-01 2022 10 01 |
2. | 2022-10-02 2022 10 02 |
3. | 2022-10-03 2022 10 03 |
4. | 2022-10-04 2022 10 04 |
5. | 2022-10-05 2022 10 05 |
+------------------------------------+
.
. clear
. input str20 email
email
1. "张三@gdufe.edu.cn"
2. "李四@gdufe.edu"
3. "王五@gdufe"
4. end
. list
+-------------------+
| email |
|-------------------|
1. | 张三@gdufe.edu.cn |
2. | 李四@gdufe.edu |
3. | 王五@gdufe |
+-------------------+
. split email, parse("@")
variables created as string:
email1 email2
. list
+-------------------------------------------+
| email email1 email2 |
|-------------------------------------------|
1. | 张三@gdufe.edu.cn 张三 gdufe.edu.cn |
2. | 李四@gdufe.edu 李四 gdufe.edu |
3. | 王五@gdufe 王五 gdufe |
+-------------------------------------------+
. drop email1 email2
. split email, parse(".") generate(web_addr)
variables created as string:
web_addr1 web_addr2 web_addr3
. list
+------------------------------------------------------+
| email web_addr1 web_ad~2 web_ad~3 |
|------------------------------------------------------|
1. | 张三@gdufe.edu.cn 张三@gdufe edu cn |
2. | 李四@gdufe.edu 李四@gdufe edu |
3. | 王五@gdufe 王五@gdufe |
+------------------------------------------------------+
. 将字符转换为数值的函数为real(s),将数值转换为字符的函数为string(n)。
di real("5.2")+1
di real("hello")
di string(12345)
clear
set obs 10
gen x = _n+47
gen y = char(x) // 通过help char()查看帮助
gen z = real(y)
gen z1 = string(z)
. di real("5.2")+1
6.2
. di real("hello")
.
. di string(12345)
12345
.
. clear
. set obs 10
Number of observations (_N) was 0, now 10.
. gen x = _n+47
. gen y = char(x) // 通过help char()查看帮助
. gen z = real(y)
. gen z1 = string(z)
. 去除空格主要是通过函数strtrim()以及ustrtrim()函数来完成。
di stritrim("hello there")
di strltrim(" this")
di ustrltrim(" 中文")
di strrtrim("this ")
di strrtrim("中文 ")
di strtrim(" this ")
di ustrtrim(" 中文 ")
di trim(" this ")
. di stritrim("hello there")
hello there
. di strltrim(" this")
this
. di ustrltrim(" 中文")
中文
. di strrtrim("this ")
this
. di strrtrim("中文 ")
中文
. di strtrim(" this ")
this
. di ustrtrim(" 中文 ")
中文
. di trim(" this ")
this
. 正则表达式是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为”元字符”),可以实现字符串函数中类似定位函数strpos()、替换函数subinstr()的复杂功能,例如可以实现找出以数字开头、以字母结尾的一段字串。这部分内容我们放在进阶内容介绍。
前面我们介绍过,可以使用generate命令生成新的变量,generate命令能够跟表达式和多数函数一起连用3,而命令egen4可以和函数一起连用,实现一些更加复杂的功能来生成变量。你可以通过help egen查看相关的函数。egen命令的语法结构如下:

常用的egen函数包括:
求和函数有两个:sum()和total(),当他们与egen连用的时候,都可以计算变量所有取值的和。sum()函数还可以与变量generate连用,实现计算“累加和”。rowtotal()函数可以按行计算多个变量每一行取值的和。
clear
set obs 5
gen x = _n
summarize x
sum x, detail
gen sum_x1 = sum(x)
egen sum_x2 = sum(x)
egen total_x = total(x) // 注意对比sum和total与egen连用的结果
egen row_total = rowtotal(x sum_x1 sum_x2)
list
. clear
. set obs 5
Number of observations (_N) was 0, now 5.
. gen x = _n
. summarize x
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
x | 5 3 1.581139 1 5
. sum x, detail
x
-------------------------------------------------------------
Percentiles Smallest
1% 1 1
5% 1 2
10% 1 3 Obs 5
25% 2 4 Sum of wgt. 5
50% 3 Mean 3
Largest Std. dev. 1.581139
75% 4 2
90% 5 3 Variance 2.5
95% 5 4 Skewness 0
99% 5 5 Kurtosis 1.7
.
. gen sum_x1 = sum(x)
. egen sum_x2 = sum(x)
. egen total_x = total(x) // 注意对比sum和total与egen连用的结果
. egen row_total = rowtotal(x sum_x1 sum_x2)
. list
+------------------------------------------+
| x sum_x1 sum_x2 total_x row_to~l |
|------------------------------------------|
1. | 1 1 15 15 17 |
2. | 2 3 15 15 20 |
3. | 3 6 15 15 24 |
4. | 4 10 15 15 29 |
5. | 5 15 15 15 35 |
+------------------------------------------+
. 在上面的例子中,代码egen row_total = rowtotal(x sum_x1 sum_x2)的功能是将变量x、sum_x1和sum_x2按行求和,这和我们之前讲过的“加法运算”是一样的,等价的写法是gen row_total = x+sum_x1+sum_x2。
的确在上面的例子中两种方法的结果是一样的,但是如果变量中有缺失值,函数rowtotal()会忽略缺失值,使用非缺失值进行运算,而加法运算的结果将会是缺失值。
clear
set obs 5
gen x = _n
gen sum_x = sum(x)
egen total_x = total(x)
replace x = . in 4
egen row_total1 = rowtotal(x sum_x total_x)
gen row_total2 = x+sum_x+total_x当然,rowtotal()函数也可以加入,miss的option将包含缺失值的行结果全部改为缺失,实现与“加法运算”一样的效果。具体可以通过help egen查看rowtotal()函数的帮助文档。
在之前的教程中,我们介绍过命令summarize可以给出变量的描述性统计信息,我们也可以使用函数将特定描述系统统计值存放到变量中。例如,mean(var1)函数用于计算变量var1的平均值5 sd()函数用于计算变量的标准差,min()函数、max()函数、median()函数、skew()函数、kurt()函数分别用于计算最小值、最大值、中位数、偏度和峰度等。
这些函数默认都是“纵向”计算,也就是针对某个变量的所有取值计算描述性统计。也有一些类似的函数可以实现“横向”计算,rowmean(varlist)函数就是计算多个变量每一行对应的均值,rowsd()、rowmin()、rowmax()函数等也可以实现类似的横向计算功能。
clear
set obs 5
gen x = _n
summarize x
sum x, detail
// 纵向计算
egen mean_x = mean(x)
egen sd_x = sd(x)
egen max_x = max(x)
egen min_x = min(x)
egen median_x = median(x)
// 横向计算
gen sum_x = sum(x)
egen sum_x2 = sum(x)
egen rowavg = rowmean(x sum_x sum_x2)
egen rowmax = rowmax(x sum_x sum_x2)
egen rowmin = rowmin(x sum_x sum_x2)
egen rowsd = rowsd(x sum_x sum_x2)
egen rowmedian = rowmedian(x sum_x sum_x2)
list x row*
. clear
. set obs 5
Number of observations (_N) was 0, now 5.
. gen x = _n
. summarize x
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
x | 5 3 1.581139 1 5
. sum x, detail
x
-------------------------------------------------------------
Percentiles Smallest
1% 1 1
5% 1 2
10% 1 3 Obs 5
25% 2 4 Sum of wgt. 5
50% 3 Mean 3
Largest Std. dev. 1.581139
75% 4 2
90% 5 3 Variance 2.5
95% 5 4 Skewness 0
99% 5 5 Kurtosis 1.7
.
. // 纵向计算
.
. egen mean_x = mean(x)
. egen sd_x = sd(x)
. egen max_x = max(x)
. egen min_x = min(x)
. egen median_x = median(x)
. // 横向计算
. gen sum_x = sum(x)
. egen sum_x2 = sum(x)
. egen rowavg = rowmean(x sum_x sum_x2)
. egen rowmax = rowmax(x sum_x sum_x2)
. egen rowmin = rowmin(x sum_x sum_x2)
. egen rowsd = rowsd(x sum_x sum_x2)
. egen rowmedian = rowmedian(x sum_x sum_x2)
. list x row*
+------------------------------------------------------+
| x rowavg rowmax rowmin rowsd rowmed~n |
|------------------------------------------------------|
1. | 1 5.666667 15 1 8.082904 1 |
2. | 2 6.666667 15 2 7.234178 3 |
3. | 3 8 15 3 6.244998 6 |
4. | 4 9.666667 15 4 5.507571 10 |
5. | 5 11.66667 15 5 5.773503 15 |
+------------------------------------------------------+
. 分组函数group(varname)会按照变量varname的取值生成一个新的变量,取值为1,2,3,…N (N对应原变量varname的取值的数量)。当然group(varlist)函数也可以作用于多个变量,此时生成的新变量的取值个数取决于变量列表varlist中所有变量的取值的组合的数量。
sysuse auto, clear
tab rep78
egen group_race = group(rep78)
tab rep78 foreign
egen group_race_sex = group(rep78 foreign)
. sysuse auto, clear
(1978 automobile data)
. tab rep78
Repair |
record 1978 | Freq. Percent Cum.
------------+-----------------------------------
1 | 2 2.90 2.90
2 | 8 11.59 14.49
3 | 30 43.48 57.97
4 | 18 26.09 84.06
5 | 11 15.94 100.00
------------+-----------------------------------
Total | 69 100.00
. egen group_race = group(rep78)
(5 missing values generated)
.
. tab rep78 foreign
Repair |
record | Car origin
1978 | Domestic Foreign | Total
-----------+----------------------+----------
1 | 2 0 | 2
2 | 8 0 | 8
3 | 27 3 | 30
4 | 9 9 | 18
5 | 2 9 | 11
-----------+----------------------+----------
Total | 48 21 | 69
. egen group_race_sex = group(rep78 foreign)
(5 missing values generated)
. 函数pctile(exp), p(#)用于计算给定表达式exp的#分位数。这个函数在对数据分组的时候较为有用。例如,一个可能的场景是将数据按照某个变量的大小分为3组6,这时候就可以按照33%分位数、67%分位数作为分割点将数据分组。
sysuse auto, clear
egen p33 = pctile(price), p(33)
egen p67 = pctile(price), p(67)
gen group = .
replace group = 1 if (price <= p33)
replace group = 2 if (price > p33) & (price <= p67)
replace group = 3 if (price > p67)
tab group
tabstat price, by(group) statistics(N mean median min max)
. sysuse auto, clear
(1978 automobile data)
. egen p33 = pctile(price), p(33)
. egen p67 = pctile(price), p(67)
. gen group = .
(74 missing values generated)
. replace group = 1 if (price <= p33)
(25 real changes made)
. replace group = 2 if (price > p33) & (price <= p67)
(25 real changes made)
. replace group = 3 if (price > p67)
(24 real changes made)
. tab group
group | Freq. Percent Cum.
------------+-----------------------------------
1 | 25 33.78 33.78
2 | 25 33.78 67.57
3 | 24 32.43 100.00
------------+-----------------------------------
Total | 74 100.00
. tabstat price, by(group) statistics(N mean median min max)
Summary for variables: price
Group variable: group
group | N Mean p50 Min Max
---------+--------------------------------------------------
1 | 25 4028.6 4060 3291 4482
2 | 25 5101.36 5079 4499 5886
3 | 24 9499.167 9252 5899 15906
---------+--------------------------------------------------
Total | 74 6165.257 5006.5 3291 15906
------------------------------------------------------------
. 截止到目前为止,我们已经学习了很多的命令,option的存在可以在命令的核心功能基础上,实现更加丰富的功能。 其实,option可以出现在很多位置。例如,命令egen p33 = pctile(price), p(33)中,p(33)是函数pctile()的option,而命令tabstat price, by(group) statistics(N mean median min max)中by(group)和statistics(N mean median min max)是命令tabstat的option。后面章节当我们介绍statsby的命令时,你还会遇到option也可以有option的情况。
egen中与排序有关的函数是rank(),它的作用是根据变量(或者变量的表达式)进行排序(默认是按照升序),并生成一个新的变量用于存放这个排序的序号。如果取值有相同的情况,则通过option指定如何处理。具体可以参见egen命令的帮助文档。
sysuse auto, clear
sort price
egen rank_price = rank(price)
tab rank_price
egen rank_headroom1 = rank(headroom),field
egen rank_headroom2 = rank(headroom),track
egen rank_headroom3 = rank(headroom),unique
. sysuse auto, clear
(1978 automobile data)
. sort price
. egen rank_price = rank(price)
. tab rank_price
rank of |
(price) | Freq. Percent Cum.
------------+-----------------------------------
1 | 1 1.35 1.35
2 | 1 1.35 2.70
3 | 1 1.35 4.05
4 | 1 1.35 5.41
5 | 1 1.35 6.76
6 | 1 1.35 8.11
7 | 1 1.35 9.46
8 | 1 1.35 10.81
9 | 1 1.35 12.16
10 | 1 1.35 13.51
11 | 1 1.35 14.86
12 | 1 1.35 16.22
13 | 1 1.35 17.57
14 | 1 1.35 18.92
15 | 1 1.35 20.27
16 | 1 1.35 21.62
17 | 1 1.35 22.97
18 | 1 1.35 24.32
19 | 1 1.35 25.68
20 | 1 1.35 27.03
21 | 1 1.35 28.38
22 | 1 1.35 29.73
23 | 1 1.35 31.08
24 | 1 1.35 32.43
25 | 1 1.35 33.78
26 | 1 1.35 35.14
27 | 1 1.35 36.49
28 | 1 1.35 37.84
29 | 1 1.35 39.19
30 | 1 1.35 40.54
31 | 1 1.35 41.89
32 | 1 1.35 43.24
33 | 1 1.35 44.59
34 | 1 1.35 45.95
35 | 1 1.35 47.30
36 | 1 1.35 48.65
37 | 1 1.35 50.00
38 | 1 1.35 51.35
39 | 1 1.35 52.70
40 | 1 1.35 54.05
41 | 1 1.35 55.41
42 | 1 1.35 56.76
43 | 1 1.35 58.11
44 | 1 1.35 59.46
45 | 1 1.35 60.81
46 | 1 1.35 62.16
47 | 1 1.35 63.51
48 | 1 1.35 64.86
49 | 1 1.35 66.22
50 | 1 1.35 67.57
51 | 1 1.35 68.92
52 | 1 1.35 70.27
53 | 1 1.35 71.62
54 | 1 1.35 72.97
55 | 1 1.35 74.32
56 | 1 1.35 75.68
57 | 1 1.35 77.03
58 | 1 1.35 78.38
59 | 1 1.35 79.73
60 | 1 1.35 81.08
61 | 1 1.35 82.43
62 | 1 1.35 83.78
63 | 1 1.35 85.14
64 | 1 1.35 86.49
65 | 1 1.35 87.84
66 | 1 1.35 89.19
67 | 1 1.35 90.54
68 | 1 1.35 91.89
69 | 1 1.35 93.24
70 | 1 1.35 94.59
71 | 1 1.35 95.95
72 | 1 1.35 97.30
73 | 1 1.35 98.65
74 | 1 1.35 100.00
------------+-----------------------------------
Total | 74 100.00
. egen rank_headroom1 = rank(headroom),field
. egen rank_headroom2 = rank(headroom),track
. egen rank_headroom3 = rank(headroom),unique
. 无论是generate命令还是egen命令,都可以和by varlist连用进行分组运算,实现新生成的变量在不同分组内的取值不同。例如下面的代码将分别计算国内汽车和进口骑车的平均价格,并存放到一个新的变量中:
sysuse auto, clear
bysort foreign: egen avg_price = mean(price)
list foreign price avg_price in 1/5
list foreign price avg_price in -5/-1
. sysuse auto, clear
(1978 automobile data)
. bysort foreign: egen avg_price = mean(price)
. list foreign price avg_price in 1/5
+-----------------------------+
| foreign price avg_pr~e |
|-----------------------------|
1. | Domestic 4,099 6072.423 |
2. | Domestic 4,749 6072.423 |
3. | Domestic 3,799 6072.423 |
4. | Domestic 4,816 6072.423 |
5. | Domestic 7,827 6072.423 |
+-----------------------------+
. list foreign price avg_price in -5/-1
+-----------------------------+
| foreign price avg_pr~e |
|-----------------------------|
70. | Foreign 7,140 6384.682 |
71. | Foreign 5,397 6384.682 |
72. | Foreign 4,697 6384.682 |
73. | Foreign 6,850 6384.682 |
74. | Foreign 11,995 6384.682 |
+-----------------------------+
. 很多情况下,分组计算之后,我们无需保留所有的观测值,而是只需要每个分组内保留一个观测值,例如在上面的例子中,在我们计算得到国产车与进口车的价格后,我们只需要在foreign取值分组中各保留一个观测值即可,因为每个foreign取值分组内avg_price的数值都是相同的。
bysort foreign: keep if _n == 1
list foreign avg_price
. bysort foreign: keep if _n == 1
(72 observations deleted)
. list foreign avg_price
+---------------------+
| foreign avg_pr~e |
|---------------------|
1. | Domestic 6072.423 |
2. | Foreign 6384.682 |
+---------------------+
. 1.下面的代码可以自动生成2020年1月到2022年12月的年月指标,
clear
set obs 36
gen year_month = _n-1+ym(2020,1)
compress
list in 1/10请编辑代码逐小题实现如下各项功能:
year_month的显示格式为“YYYY-MM”(例如2020-01)。first_day,取值为变量year_month取值对应年月的第一天,并调整变量first_day的显示格式为“YYYY-MM-DD”(例如2020-01-01)。first_day生成变量year、month和day,分别是对应的年份、月份和日期。last_day,取值为变量year_month取值对应年月的最后一天,并调整变量last_day的显示格式为“YYYY-MM-DD”(例如2020-01-31)。(提示:利用在Stata中无论是日期、还是年月,本质上都是一些间隔为1的整数序列这一性质和第c步骤中计算年月内第一天的函数)year变量的升序和month变量的降序对数据进行排序。2.下面的代码给能够生成2021年1月1日到2021年12月31日的日期序列
clear
set obs 365
gen my_date = _n-1+mdy(1,1,2021)
compress
list in 1/10请编辑代码逐小题实现如下各项功能:
my_date生成变量year、month和day,(注意,变量生成后,用compress命令将三个变量的类型都压缩为整数型int)year、month和day得到8位整数“yyyymmdd”,存放到变量my_date1中。例如20201年1月1日的year、month和day的取值分别是2021,1和1,那么my_date1的取值应该是20210101,用fomrat修改变量my_date1的显示格式为%8.0f(仔细观察这些数据结果,你会发现它们和你预想的8位整数有细微差异,主要是来自于变量类型导致的精度问题,我们将在下一个小题中尝试解决它)。string函数(而不是命令)从数值型变量year、month、day生成字符型变量year_str,month_str和day_str,然后将year_str,month_str和day_str变量拼接为8位字符(例如20210101)并保存在变量my_date_str中(提示:在拼接前,你要注意有一些月份、日期是个位数字,我们的目标到8个字符长度的日期,因此这种情况需要补零)。my_date_str通过destring命令(而不是函数)转换为数值型变量,新变量名为my_date2(注意,不是转换成相对于1960年1月1日的整数,而是对应的8位整数),基于变量my_date2(8位整数)计算其中的年、月和日,分别保存为变量year2,month2和day2,例如整数20210304对应的年是2021、月是3,日是4。(提示:可以使用int()函数、mod()函数)year和month,生成年月变量my_ym,并调整显示格式为YYYY-MM也就是2021-01的形式。然后计算每个年月对应的第一天和最后一天的日期,分别存放在my_fist_day和my_last_day中,两个日期变量的显示格式都调整为YYYY-MM-DD也就是2021-01-01的形式。(提示:计算最后一天时可以利用在Stata中无论是日期、还是年月,本质上都是一些间隔为1的整数序列这一性质和计算年月内第一天的函数来完成)3.文件IPO_Ipobasic.xlsx是从CSMAR数据库下载的我国A股上市公司从1990年12月10日以来的招股及上市基本情况。文件中的前3行分别是指标英文名称、指标中文含义、指标的单位。该数据集共计有147个指标,有效数据5571条。该数据集中每一条观测值代表我国A股市场中的一次IPO的相关数据。文件IPO_Ipobasic.txt是相应的指标说明文件,其中给出了数据文件IPO_Ipobasic.xlsx中每一个指标的含义。 请编辑代码逐小题实现如下功能:
IPO_Ipobasic.xlsx读入Stata中,要求将第1行作为变量名,保留如下变量列:Stkcd [证券代码] 、Listdt [上市日期]、Ipostpbdt [招股说明书发表日期];然后将数据然后删除原Excel文件中的第2行、第3行这两行无效数据;然后通过命令将Stkcd转换为数值型变量,通过日期相关的函数将Listdt、Ipostpbdt转换为日期型变量,并将显示格式调整为YYYY-MM-DD;然后删除Listdt或Listdt缺失的观测值;最后仅保留2016年-2022年间(上市日期为2016年1月1日到2022年12月31日之间)的新股发行数据,将处理后的文件保存为IPO_data.dta。IPO_data.dta出发,进一步生成一个新变量days_gap计算上市公司从“招股说明书发表日期”到“上市日期”之间的时间间隔(定义为两个日期的差值),剔除days_gap为缺失值的样本。我们想进一步统计days_gap的取值分布情况,在上一小问的基础上,将整个数据集基于变量days_gap分为3组:分组变量名为group,当days_gap的取值不大于7天时,group取值为1、当days_gap的取值大于7天但是不大于14天时group取值为2、当当days_gap的取值大于14天时,group取值为3,通过命令列出group变量每个取值的观测值数量(也就是days_gap三个取值范围内IPO的数量)。IPO_data.dta出发,统计每个自然月(即1月、2月、…、12月,无论上市日期的年份是否相同,我们只按照上市日期的自然月份进行统计)内IPO记录的数量。自然月变量命名为natural_month;IPO数量变量命名为ipo_number,该变量内存放的是每个观测值对应的自然月(1,2,…,12)内IPO的数量;完成计算后,最终数据中仅保留自然月变量natural_month和IPO数量变量ipo_number,并且每个自然月仅保留一条观测值;最后给出变量ipo_number的描述性统计信息(观测值、均值、标准差、最小值、最大值)。4.文件stock_trade_data202101.xlsx是我们在第二章使用过的个股交易数据,它是从CCER数据库下载得到,涵盖了全部A股上市公司在2021年1月的日度交易数据。你可以从课程QQ群文件——data目录下获取该数据文件。请编辑代码完成如下任务:
stock_trade_data202101.xlsx读入Stata,要求:以第一行的数据为变量名,然后仅保留股票代码、日期、收盘价、回报率不考虑分红四个变量,然后将上述四个变量转换为数值型,其中日期注意使用日期函数转换,并格式化为YYYY-MM-DD,将数据保存为stock_trade_data.dta。stock_trade_data.dta出发,计算每支股票每个月(为了防止数据集过大,此数据集中只有2021年1月这一个月的数据,但你可以假设有很多月份,尝试把代码写得更稳健,适合有多个月的情况)的平均收盘价格、收盘价格的标准差、最高收盘价格、最低收盘价格,分别保存在变量avg_close,sd_close,max_close和min_close中(都是需要新生成的变量)。stock_trade_data.dta出发,基于收盘价变量,分别计算计算日度收益率和日度对数收益率,(t日收益率定以为:t日收盘价/t-1日收盘价-1;t日的对数收益率定以为:ln(t日收盘价)-ln(t-1日收盘价),这里ln()是自然对数),两个收益率指标分别保存在变量ret_close和ln_ret_close。(提示:可以通过收盘价[_n-1]得到t-1日的收盘价格),查看ret_close和log_ret_close变量以及回报率不考虑分红变量的描述性统计(summarize命令),直观感受你计算出的两个收益率指标是否合理(当收益率很小时,这两种定义方式互为等价无穷小量)。stock_trade_data.dta出发,将回报率不考虑分红指标作为股票日度收益率的衡量指标,基于该指标计算每支股票2021年1月的月度累计收益率(复利),新变量命名为monthly_ret,累计收益率定义为: (1+r_1)*(1+r_2)*\cdots*(1+r_N)-1,其中 N 为当月该股票的交易日的天数 [提示:可以通过取对数将乘法转换为加法]。stock_trade_data.dta出发,将回报率不考虑分红指标作为股票日度收益率的衡量指标,基于该指标计算每支股票2021年1月中收益率最高的3天内的平均收益率(!注意不是2021年1月所有天的平均收益率,而是回报率不考虑分红指标最大的3天中回报率不考虑分红指标的平均值),将该数据存放在变量max_3d_ret中;计算完成后,每支股票、每个“年月”仅保留一个观测值(注意,保留下来的观测值中max_3d_ret的取值必须是对应股票对应年月的月收益率 。5.文件上市公司信息-Wind-2023.xlsx中给出了上市公司的股票代码、公司名称、注册地址、办公地址、主营产品类型、省份、城市的信息,请基于该数据完成如下任务:
上市公司信息-Wind-2023.dta。 num_main_product中。例如,平安银行(股票代码000001)的主营产品类型为存贷款业务、国际业务、机构业务、结算业务、人民币理财、外汇理财、银行卡、证券业务,因此该公司的主营产品数量为8。这里N是代表月份的数字表达01-12,字母M则代表英文简写的表达Jan-Dec。↩︎
需要注意的是,Stata里的周和我们传统意义上的周不太一样,我们默认一周都是从周一开始、周日结束(或者一些西方国家认为从周日开始,周六结束),当一年中的第一周不是从周一开始,我们将第一天到最近的周日作为第一周。但在Stata中,每一年的第一周是从当你第一天到第七天的范围,调整方法可以参考这篇博客文章↩︎
能够和generate 命令连用的函数包括:数学函数、字符串函数、日期时间函数和接下来要介绍的一个较为特殊的函数sum()——它既可以与generate一起使用,也可以与egen命令一起使用,但功能有一定差别。↩︎
从命令的名称也可以看出来,egen 是extened generate(扩展的generate)的含义。↩︎
如果你查看帮助文档,会发现mean()函数的输入是表达式exp而不是变量varlist或varname ,mean(exp),是你可以将这里的exp是基于变量的表达式,例如(var1+var2),mean((var1+var2))则是一个类似于数学中复合函数的情况。↩︎
这种分组分析的方式在资产定价的研究中非常常见。↩︎