10 公司金融领域常见指标计算
在本章中,我们将基于论文《自由现金流量创造力与违约风险——来自A股公司的经验证据》,向大家展示公司金融领域的论文中一些常见指标的计算方法。该论文发表于《金融研究》期刊2020年第12期。大家可以从链接 http://www.jryj.org.cn/CN/Y2022/V510/I12/168下载该论文。
10.1 计算目标
公司金融领域的研究对象通常是上是公司,所用的数据大多数都是基于上市公司的财务报表数据构造的指标得到。因而通常是“公司x年度”的结构,也就是说最终的数据通常是每个公司、每个年度有一个观测值1。
请大家提前阅读论文(主要阅读“四、研究设计”部分),我们将基于CSMARA数据库的数据文件,计算表1中的(部分)指标。

上述表格中的变量大致有如下几个来源:
- 财务报表数据。数据来自于资产负债表、利润表或者现金流量表(或者它们全部)。
- 公司规模(Size)
- 有息负债率(ILev)
- 总资产收益率(ROA)
- 成长性(Growth)
- 内源融资能力(CFO_TA)
- 总资产周转率(TATurnover)
- 固定资产占比(PPE)
- 公司股东持股数据
- 第一大股东持股比例(FSH)
- 实际控制人文件
- 公司产权性质(SOE)我们根据实际控制人的性质是否为国有判断上市公司是否为国有企业
- 公司治理数据
- 独立董事占比(Outside)
- 交易数据
- 股票波动率(Vol)为了减少数据量、我们使用股票月收益率计算此指标
- 上市公司基本信息
- 上市年龄(Age)
此外,在对样本的筛选中,论文仅仅使用了非金融行业的上市公司,因此我们还需要行业分类数据,该数据也可以从上市公司基本信息文件中获得。
10.2 原始数据说明
已经为大家准备好了从CSMAR数据库下载好的数据文件,它们分别是:
- A股上市公司资产负债表 FS_Combas.xlsx
- A股上市公司利润表 FS_Comins.xlsx
- A股上市公司现金流量表 FS_Comscfd.xlsx
- A股上市公司前十大股东持股文件 CG_Sharehold.xlsx, CG_Sharehold1.xlsx
- A股上市公司董事会结构表 CG_ManagerShareSalary.xlsx
- A股上市公司公司基本情况 TRD_Co.xlsx
- A股上市公司月度收益文件 TRD_Mnth.xlsx
- A股上市公司年度收益及市值文件 TRD_Year.xlsx
数据范围从每支股票上市起到2022年2。
每个数据文件有两类文件:excel格式的数据,txt格式的是变量说明。如果数据量太大,CSMAR会拆分成多个Excel文件(在我们的数据中,仅有十大股东持股文件拆分成了两个excel文件)。txt格式的文件也很有帮助,有时候会提供一些数据中指标的取值代表含义的额外说明。
以下是每一个数据表中与计算指标直接相关的变量信息3
资产负债表(FS_Combas.xlsx)
资产总计、固定资产净额、负债合计、流动负债合计、非流动负债合计、短期借款、交易性金融负债、一年内到期的非流动负债、长期借款、应付债券、长期应付款
利润表 (FS_Comins.xlsx)
净利润、营业收入4、利息支出
现金流量表 (FS_Comscfd.xlsx)
经营活动净现金流量净额、投资活动现金流入小计、投资活动现金流出小计
十大股东文件 (CG_sharehold.xlsx, CG_Sharehold1.xlsx)
股东名称、持股排名、持股数量、持股比例、股份性质
实际控制人文件 (HLD_Contrshr.xlsx)
实际控制人性质
董事会相关文件 (CG_ManagerShareSalary.xlsx)
董事人数(含董事长)、独立董事人数
个股月度收益率数据 (TRD_Mnth.xlsx)
考虑现金红利再投资的月个股回报率、月个股总市值
个股年度收益率数据 (TRD_Year.xlsx)
考虑现金红利再投资的年个股回报率
公司基本信息文件 (TRD_Co.xlsx)
上市日期、行业分类
10.3 指标复现流程
我将整个指标计算的流程分为了前后关联的四个步骤:
- 导入原始数据并转存dta文件
- 预处理
- 计算单个指标
- 合并指标文件
下面逐一介绍这些要点。
10.3.1 step1. 导入原始数据
这一步主要是读入excel文件,并保存为dta文件
从CSMAR数据库中下载的文件(Excel格式)第1行为变量名、第2行为变量的含义、第3行为变量的单位。下面的代码以资产负债表为例,用于实现如下功能: - 将Excel格式的原始数据读入Stata - 第1行作为变量名称、第2行和第3行作为变量标签、其余行为数据内容 - 将数据尽可能转换为数值型
此外,需要注意的是,当excel数据文件大于40MB时,读入Stata会有一个报错提示“file FS_Combas.xlsx too big”,所以我们增加了一行代码set excelxlsxlargefile on。关于这个问题的讨论,可以查看Stckoverflow上的讨论。
clear all
set more off
set excelxlsxlargefile on
global PATH "C:/StataClass/chap_paper_corp"
// 数据存放在 C:/StataClass/chap_paper_corp 下的 data 目录下
import excel using "${PATH}/data/FS_Combas.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
save "${PATH}/data/FS_Combas.dta", replace 10.3.2 step2. 数据的预处理
预处理阶段,我们主要是在第一步的基础上,对数据做进一步的清洗,例如将所有的日期转换为日期型变量、以及仅保留需要的指标(部分数据下载的文件中变量有多余的)、调整变量名为有含义的名称(财务报表数据中部分指标只是数字和字母的简单组合,不够直观)。
10.3.2.1 财务报表数据的处理
CSMAR中下载的财务报表有如下几个特点需要注意:
- 涵盖了季度报表、半年度报表、年度报表和年初报表(即上一年年末)报表数值。可以通过会计年度
Accper指标区分,通过选取会计年度是年底日期的观测值,即可提取出年报数据; - 涵盖了母公司报表与合并财务报表两类,我们使用“合并财务报表“
- 财务报表科目非常多,导致原始数据很大,我们在下载数据的时候有两种思路:1.将全部原始数据下载到本地,通过程序筛选出需要的指标;2.下载的时候仅包含需要的指标。两种方式都是可以的,但是对于大家来说建议选择第1种方案,防止在研究后续进展中需要新的数据。为了演示方便,我们提供给大家的数据只包含了计算变量所必须的指标。
因此,在财务报表(资产负债表、利润表和现金流量表)的数据预处理中,我们主要做了如下工作:
- 仅保留年报数据
- 仅保留合并报表数据
- 处理日期(字符转换为日期型)
- 删除无关变量,将变量换成有意义的名称
下面的代码以资产负债表为例,展示了预处理的过程:
// (1) 资产负债表预处理
use "${PATH}/data/FS_Combas.dta", clear
// 保留年报数据
keep if month(date(Accper,"YMD"))==12 & day(date(Accper,"YMD"))==31
// 保留合并报表数据
keep if Typrep == "A"
// 处理日期
gen temp = date(Accper,"YMD")
destring Accper, replace force
replace Accper = temp
drop temp
format Accper %tdCY-N-D
// 删除无用变量、改名
drop ShortName Typrep
rename A001212000 fix_asset
rename A001000000 ttl_asset
rename A002101000 short_loan
rename A002105000 trd_fian_liability
rename A002125000 non_curnt_loan_1yr
rename A002100000 curnt_debt
rename A002201000 long_loan
rename A002203000 bond_payable
rename A002204000 long_payable
rename A002000000 ttl_debt
rename A002200000 non_curr_debt
compress
save "${PATH}/process/资产负债表.dta", replace 10.3.2.2 十大股东文件预处理
该数据提供了上市公司前十大(部分还囊括了十一到一百)的股东持股比例。但是这些信息的来源有些是在年报中公告的,有些可能不是,为了与其他数据保持一致,我们仅使用年年报信息(当然,年报也是最主要的信息来源),可以通过公告日期(Reptdt)进行区分。 在预处理阶段,我们做了如下工作:
1.仅保留年报的数据 2.仅保留前十大股东的持股比例
10.3.2.3 实际控制人文件预处理
与十大股东持股文件类似,我们也仅仅保留了年报数据。
10.3.2.4 董事会结构文件预处理
与十大股东持股文件类似,我们也仅仅保留了年报数据。 另外,董事会构成信息有两个信息统计口径,即是否统计年底前离职、退休的董事,该数据集分别按照这两种口径提供了两类结果。我们这里使用了包含离职、退休人员的口径(可以使用指标StatisticalCaliber进行判断)。
10.3.2.5 个股月收益率文件预处理
将字符型年月转换为数值型。
10.3.2.6 个股月收益率文件预处理
将字符日期转换为数值型
10.3.2.7 公司基本信息文件预处理
将字符型的上市日期转换为数值型
10.3.3 step3. 分别计算每一个指标
1.计算公司规模 Size
该指标定义为公司年末总资产的自然对数,为了保证Size的数值不会太大,我们将总资产的单位调整为了“亿元”。
2.计算有息负债率ILev
有息负债率定义为付利息的负债总和与公司年末总资产的比值,这些都来自于资产负债表。有一点需要注意的是,部分科目的指标取值为缺失值,直接加总会导致有息负债的加总之和为缺失(回忆一下,我们介绍过缺失值与任何数值的的运算结果仍然都是缺失值),因此我们这里使用了rowtotal()函数来汇总所有的有息负债科目值。
3.计算总资产负债率ROA
该指标定义为净利润除以年初年末总资产的平均值(平均资产)。 年初资产其实也就是前一年末的总资产,我们一共介绍了两种计算平均资产的方法,这里介绍第一种(在计算“内源融资能力CFO_TA指标时用了第二种):
我们将“公司x年度”的总资产数据中的“年份变量”+1,这样总资产里存放的就变成了前一年末(t-1年)的总资产lst_yr_ttl_asset,然后将这个数据与原来的总资产数据(t年)文件通过merge命令合并在一起,然后我们使用rowmean()函数计算ttl_asset与lst_yr_ttl_asset的平均值。
另外,净利润指标来自于利润表、总资产来自于资产负债表。两个数据集需要使用merge命令合并在一起才能计算最终指标。
4.计算增长率Growth
增长率定义为公司每年的营业收入相对于前一年营业收入的增长率,具体来说,定义为 Sales_t/Sales_{t-1}-1。这里我们使用了面板数据的操作:差分运算和滞后期运算。
命令 xtset Stkcd year 将数据设定为面板格式,其中Stkcd为个体指标,year是时间指标。L1.varname回计算指标varname前一期的数值,而D1.varname=varname-L1.varname。
5.计算内源融资能力CFO_TA
我们采用了与计算增长率Growth指标类似的方法(基于面板数据的滞后运算)得到了上市公司前一年的总资产,并在此基础上计算了年初和年末的平均资产。 另外,经营活动产生的净现金流来自于现金流量表,两个表的数据需要使用命令merge合并在一起。
6.计算总资产周转率TATurnover
与计算CFO_TA的思路类似
7.计算第一大股东持股比例FSH
只需要保留排名第一位的股东的持股比例即可。
8.计算独立董事比例
没有什么特别的
9.计算固定资产占比
没有什么特别的
10.计算公司产权性质
我们主要依赖控股股东的性质是否是国有来判断,CSMAR将实际控制人的类型进行了划分并做了分类,分类结果参见如下图所示

可以看出,如果编码是1100、2000、2100和2120的都是国有企业。
另外,这个数据集中,关于控股股东的判断,有两种来源——一是年报的公布,二是根据持股链条推算(CSMAR做的)得到,我们这里使用第二种来源(更加精确);另外,控股股东可能有多条记录(联合持股或者有其他关联关系),只要其中有一条(或者说一个控股股东)属于国有性质,我们就认为该年度该公司的控股股东为国有。 代码如下:
use "${PATH}/process/实际控制人性质.dta", clear
bysort Stkcd Reptdt controller_code: keep if _n == 1
gen SOE = 0
replace SOE = 1 if strpos(controller_code,"1100")
replace SOE = 1 if strpos(controller_code,"2000")
replace SOE = 1 if strpos(controller_code,"2100")
replace SOE = 1 if strpos(controller_code,"2120")
sort Stkcd Reptdt SOE
bysort Stkcd Reptdt: keep if _n == _N
gen year = year(Reptdt)
keep Stkcd year SOE
compress
save "${PATH}/process/variable_SOE.dta", replace 11.上市年两
上市年龄是指截止到t年,距离公司上市日期(Listdt)过去的年份的数量。我们的代码思路是:将上市公司的基本信息文件中提取出上市日期(每个公司有一条观测值),然后将次数据重复33次(从1990年到2022年,即从第一支股票上市到今年),这样得到每一年每一个上市公司的年龄。
12.股票波动率
基于月收益率数据计算标准差
13.现金流创造力
注意指标中的需要计算累加值,即需要用generate命令和sum()函数
14.违约风险
按照定义,逐步完成。
10.3.4 step4. 合并单独的指标文件
使用merge命令合并第3步中计算得到的单个指标文件。使用merge命令,合并的基准变量是Stkcd和year。
另外,需要注意的有两点:第一、作者的现金创造能力指标要求上市至少10年,因此我们要求了样本需要年龄>=10;第二、我们需要用t+1年的违约风险指标与t年的其他指标进行分析,因此在合并的时候,我们将数据文件variable_EDP.dta的年度变量year-1之后才与其他数据文件进行合并
10.4 完整的股票代码
10.4.1 step1 代码
clear all
set more off
set excelxlsxlargefile on
global PATH "C:/StataClass/chap_paper_corp"
// step1. 数据读入(excel --> dta)
//
// 1.资产负债表文件
import excel using "${PATH}/data/FS_Combas.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
save "${PATH}/data/FS_Combas.dta", replace
//
// 2.利润表文件
import excel using "${PATH}/data/FS_Comins.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
save "${PATH}/data/FS_Comins.dta", replace
//
// 3.现金流量表(直接法)
import excel using "${PATH}/data/FS_Comscfd.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
save "${PATH}/data/FS_Comscfd.dta", replace
//
// 4.十大股东持股文件
import excel using "${PATH}/data/CG_Sharehold.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
save "${PATH}/data/CG_Sharehold.dta", replace
import excel using "${PATH}/data/CG_Sharehold1.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
append using "${PATH}/data/CG_Sharehold.dta"
save "${PATH}/data/CG_Sharehold.dta", replace
//
// 5.实际控制人
import excel using "${PATH}/data/HLD_Contrshr.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
save "${PATH}/data/HLD_Contrshr.dta", replace
//
// 6. 董事会结构相关文件
import excel using "${PATH}/data/CG_ManagerShareSalary.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
save "${PATH}/data/CG_ManagerShareSalary.dta", replace
//
// 7. 个股月收益率数据
import excel using "${PATH}/data/TRD_Mnth.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
save "${PATH}/data/TRD_Mnth.dta", replace
//
// 8. 个股年收益率数据
import excel using "${PATH}/data/TRD_Year.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
save "${PATH}/data/TRD_Year.dta", replace
// 9. 上市公司基本信息文件
import excel using "${PATH}/data/TRD_Co.xlsx", clear firstrow
foreach var of varlist *{
local mylabel = `var'[1]+"|"+`var'[2]
label variable `var' "`mylabel'"
}
drop in 1/2
destring _all, replace
compress
save "${PATH}/data/TRD_Co.dta", replace 10.4.2 step2 完整代码
clear all
set more off
set excelxlsxlargefile on
global PATH "C:/StataClass/chap_paper_corp"
//
// require run file "paper1-step1-read-raw-data.do"
//
// step2. 数据预处理
capture mkdir "${PATH}\process"
// (1) 资产负债表预处理
use "${PATH}/data/FS_Combas.dta", clear
// 保留年报数据
keep if month(date(Accper,"YMD"))==12 & day(date(Accper,"YMD"))==31
// 保留合并报表数据
keep if Typrep == "A"
// 处理日期
gen temp = date(Accper,"YMD")
destring Accper, replace force
replace Accper = temp
drop temp
format Accper %tdCY-N-D
// 删除无用变量、改名
drop ShortName Typrep
rename A001212000 fix_asset
rename A001000000 ttl_asset
rename A002101000 short_loan
rename A002105000 trd_fian_liability
rename A002125000 non_curnt_loan_1yr
rename A002100000 curnt_debt
rename A002201000 long_loan
rename A002203000 bond_payable
rename A002204000 long_payable
rename A002000000 ttl_debt
rename A002200000 non_curr_debt
compress
save "${PATH}/process/资产负债表.dta", replace
// (2) 利润表预处理
use "${PATH}/data/FS_Comins.dta", clear
// 保留年报数据
keep if month(date(Accper,"YMD"))==12 & day(date(Accper,"YMD"))==31
// 保留合并报表数据
keep if Typrep == "A"
// 处理日期
gen temp = date(Accper,"YMD")
destring Accper, replace force
replace Accper = temp
drop temp
format Accper %tdCY-N-D
// 删除无用变量、改名
drop ShortName Typrep
rename B001101000 sales
rename Bbd1102203 interest
rename B002000000 net_income
compress
save "${PATH}/process/利润表.dta", replace
// (3) 现金流量表预处理
use "${PATH}/data/FS_Comscfd.dta", clear
// 保留年报数据
keep if month(date(Accper,"YMD"))==12 & day(date(Accper,"YMD"))==31
// 保留合并报表数据
keep if Typrep == "A"
// 处理日期
gen temp = date(Accper,"YMD")
destring Accper, replace force
replace Accper = temp
drop temp
format Accper %tdCY-N-D
// 删除无用变量、改名
drop ShortName Typrep
rename C001100000 operating_cash_in
rename C001200000 operating_cash_out
rename C001000000 operating_cash_net
rename C002100000 invest_cash_in
rename C002200000 invest_cash_out
rename C002000000 invest_cash_net
drop operating_cash_in operating_cash_out
compress
save "${PATH}/process/现金流量表.dta", replace
// (4) 十大股东持股文件
use "${PATH}/data/CG_Sharehold.dta", clear
// 处理日期
gen temp = date(Reptdt,"YMD")
destring Reptdt, replace force
replace Reptdt = temp
drop temp
format Reptdt %tdCY-N-D
// 只保留年报数据
keep if month(Reptdt)==12 & day(Reptdt)==31
rename S0501b rank
rename S0301b sharehold
keep if rank <= 10
keep Stkcd Reptdt sharehold rank
compress
save "${PATH}/process/前十大股东持股文件.dta", replace
// (5) 实际控制人文件
use "${PATH}/data/HLD_Contrshr.dta", clear
keep if S0701a == 2
drop S0702a
keep Stkcd Reptdt S0702b
compress
rename S0702b controller_code
// 处理日期
gen temp = date(Reptdt,"YMD")
destring Reptdt, replace force
replace Reptdt = temp
drop temp
format Reptdt %tdCY-N-D
keep if month(Reptdt)==12 & day(Reptdt)==31
save "${PATH}/process/实际控制人性质.dta", replace
// (6) 董事会结构相关文件
use "${PATH}/data/CG_ManagerShareSalary.dta", clear
rename Symbol Stkcd
// 处理日期
gen temp = date(Enddate,"YMD")
destring Enddate, replace force
replace Enddate = temp
drop temp
format Enddate %tdCY-N-D
// 统计口径保留“全部工作人员(含退休、离职)
keep if StatisticalCaliber == 2
// 仅保留年报相关的数据
keep if month(Enddate)==12 & day(Enddate)==31
compress
save "${PATH}/process/董事会人数.dta", replace
// (7) 个股月收益率数据
use "${PATH}/data/TRD_Mnth.dta", clear
keep Stkcd Trdmnt Mretwd
gen temp = ym(real(substr(Trdmnt,1,4)),real(substr(Trdmnt,6,2)))
destring Trdmnt, replace force
replace Trdmnt = temp
drop temp
format Trdmnt %tmCY-N
compress
save "${PATH}/process/月收益率数据.dta",replace
// (8) 个股年收益率和市值数据
use "${PATH}/data/TRD_Year.dta", clear
keep Stkcd Trdynt Yretwd Ysmvttl
compress
save "${PATH}/process/年收益率数据.dta",replace
// (9) 上市公司基本信息文件
use "${PATH}/data/TRD_Co.dta", clear
keep Stkcd Listdt
gen temp = date(Listdt,"YMD")
destring Listdt, replace force
replace Listdt = temp
drop temp
format Listdt %tdCY-N-D
compress
save "${PATH}/process/上市日期.dta", replace 10.4.3 step3 完整代码
clear all
set more off
set excelxlsxlargefile on
global PATH "C:/StataClass/chap_paper_corp"
//
// require run file "paper1-step1-read-raw-data.do"
// "paper1-step2-preprocess.do"
//
// step3. 指标计算
// (1) 公司规模 Size
use "${PATH}/process/资产负债表.dta", clear
gen Size = ln(ttl_asset/10^8)
gen year = year(Accper)
keep Stkcd year Size
compress
save "${PATH}/process/variable_size.dta", replace
// (2) 有息负债率
use "${PATH}/process/资产负债表.dta", clear
// 注意不能直接使用加法,因为很多指标是missing vlaue,因此使用rowtotal()函数
// 也可以先将missing value 替换为 0,然后再用加法相加
egen debt = rowtotal(short_loan trd_fian_liability non_curnt_loan_1yr long_loan long_payable bond_payable)
gen ILev = debt/ttl_asset
gen year = year(Accper)
keep Stkcd year ILev
compress
save "${PATH}/process/variable_ILev.dta", replace
// (3) 总资产收益率
// a.计算平均资产
use "${PATH}/process/资产负债表.dta", clear
gen year = year(Accper)
keep Stkcd year ttl_asset
save "${PATH}/process/tempfile_ttl_asset.dta", replace
use "${PATH}/process/tempfile_ttl_asset.dta", clear
replace year = year+1
rename ttl_asset lst_yr_ttl_asset
merge 1:1 Stkcd year using "${PATH}/process/tempfile_ttl_asset.dta",
keep if _m == 3
drop _m
egen avg_asset = rowmean(ttl_asset lst_yr_ttl_asset)
keep Stkcd year avg_asset
save "${PATH}/process/tempfile_avg_asset.dta", replace
erase "${PATH}/process/tempfile_ttl_asset.dta"
// b.合并净利润,计算ROA
use "${PATH}/process/利润表.dta", clear
gen year = year(Accper)
keep Stkcd year net_income
merge 1:1 Stkcd year using "${PATH}/process/tempfile_avg_asset.dta"
keep if _m == 3
drop _m
gen ROA = net_income/avg_asset
keep Stkcd year ROA
save "${PATH}/process/variable_ROA.dta", replace
erase "${PATH}/process/tempfile_avg_asset.dta"
// (4) Growth
use "${PATH}/process/利润表.dta", clear
gen year = year(Accper)
keep Stkcd year sales
xtset Stkcd year
gen Growth = d1.sales/l1.sales
keep Stkcd year Growth
compress
save "${PATH}/process/variable_Growth.dta", replace
// (5) 内源融资能力
// a.计算平均资产
use "${PATH}/process/资产负债表.dta", clear
gen year = year(Accper)
keep Stkcd year Accper ttl_asset
xtset Stkcd year
gen lst_yr_ttl_asset = l1.ttl_asset
egen avg_asset = rowmean(ttl_asset lst_yr_ttl_asset)
keep Stkcd Accper avg_asset
// b.计算内源融资能力指标
merge 1:1 Stkcd Accper using "${PATH}/process/现金流量表.dta", keepusing(operating_cash_net) keep(match) nogenerate
gen CFO_TA = operating_cash_net/avg_asset
gen year = year(Accper)
keep Stkcd year CFO_TA
compress
save "${PATH}/process/variable_CFO_TA.dta", replace
// (6) 总资产周转率
use "${PATH}/process/资产负债表.dta", clear
gen year = year(Accper)
keep Stkcd year Accper ttl_asset
xtset Stkcd year
gen lst_yr_ttl_asset = l1.ttl_asset
egen avg_asset = rowmean(ttl_asset lst_yr_ttl_asset)
keep Stkcd Accper avg_asset
// b.计算资产周转能力指标
merge 1:1 Stkcd Accper using "${PATH}/process/利润表.dta", ///
keepusing(sales) nogenerate keep(match)
gen TATurnover = sales/avg_asset
gen year = year(Accper)
keep Stkcd year TATurnover
compress
save "${PATH}/process/variable_TATurnover.dta", replace
//
// (7) 第一大股东持股比例
use "${PATH}/process/前十大股东持股文件.dta", clear
keep if rank == 1
gen FSH = sharehold/100
gen year = year(Reptdt)
keep Stkcd year FSH
compress
save "${PATH}/process/variable_FSH.dta", replace
//
// (8) 独立董事比例
use "${PATH}/process/董事会人数.dta", clear
gen Outside = IndependentDirectorNumber/DirectorNumber
gen year = year(Enddate)
keep Stkcd year Outside
compress
save "${PATH}/process/variable_Outside.dta", replace
//
// (9) 固定资产占比
use "${PATH}/process/资产负债表.dta", clear
gen PPE = fix_asset/ttl_asset
gen year = year(Accper)
keep Stkcd year PPE
compress
save "${PATH}/process/variable_PPE.dta", replace
//
// (10) 公司产权性质
use "${PATH}/process/实际控制人性质.dta", clear
bysort Stkcd Reptdt controller_code: keep if _n == 1
gen SOE = 0
replace SOE = 1 if strpos(controller_code,"1100")
replace SOE = 1 if strpos(controller_code,"2000")
replace SOE = 1 if strpos(controller_code,"2100")
replace SOE = 1 if strpos(controller_code,"2120")
sort Stkcd Reptdt SOE
bysort Stkcd Reptdt: keep if _n == _N
gen year = year(Reptdt)
keep Stkcd year SOE
compress
save "${PATH}/process/variable_SOE.dta", replace
//
// (11) 上市年龄
use "${PATH}/process/上市日期.dta", clear
forval i_yr = 1990/2022{
use "${PATH}/process/上市日期.dta", clear
gen year = `i_yr'
keep if year >= year(Listdt)
save "${PATH}/process/tempfile_year`i_yr'.dta", replace
}
clear
forval i_yr = 1990/2022{
append using "${PATH}/process/tempfile_year`i_yr'.dta"
erase "${PATH}/process/tempfile_year`i_yr'.dta"
}
gen Age = ln(year-year(Listdt)+1)
keep Stkcd year Age
save "${PATH}/process/variable_Age.dta", replace
// (12) 股票波动率
use "${PATH}/process/月收益率数据.dta", clear
gen year = year(dofm(Trdmnt))
bysort Stkcd year: egen Vol = sd(Mretwd)
bysort Stkcd year: keep if _n == 1
keep Stkcd year Vol
compress
save "${PATH}/process/variable_Vol.dta", replace
// 现金流创造力
use "${PATH}/process/现金流量表.dta", clear
sort Stkcd Accper
drop if operating_cash_net== . | invest_cash_in == . |invest_cash_out == .
bysort Stkcd: gen sum_CFO = sum(operating_cash_net)
bysort Stkcd: gen sum_ICFI = sum(invest_cash_in)
bysort Stkcd: gen sum_OCFI = sum(invest_cash_out)
keep Stkcd Accper sum_*
merge 1:1 Stkcd Accper using "${PATH}/process/利润表.dta", keepusing(interest) keep(match) nogenerate
replace interest = 0 if interest == .
sort Stkcd Accper
bysort Stkcd: gen sum_INT = sum(interest)
gen year = year(Accper)
keep Stkcd year sum_*
gen FCFC2s = (sum_CFO+sum_ICFI-sum_INT)/sum_OCFI
keep Stkcd year FCFC2s
save "${PATH}/process/variable_FCFC2s.dta", replace
// 违约风险
// (1) 计算总市值、债务价值、年收益率、资产价值波动
use "${PATH}/process/年收益率数据.dta", clear
gen year = Trdynt
gen VE = Ysmvttl*1000
keep Stkcd year VE
compress
save "${PATH}/process/tempfile_VE.dta", replace
use "${PATH}/process/资产负债表.dta", clear
gen VD = curnt_debt+non_curr_debt*0.5
gen year = year(Accper)
keep Stkcd year VD
compress
save "${PATH}/process/tempfile_VD.dta", replace
use "${PATH}/process/年收益率数据.dta", clear
gen ret = Yretwd
gen year = Trdynt
keep Stkcd year ret
compress
save "${PATH}/process/tempfile_ret.dta", replace
use "${PATH}/process/月收益率数据.dta", clear
gen year = year(dofm(Trdmnt))
bysort Stkcd year: egen sigma_e = sd(Mretwd)
bysort Stkcd year: keep if _n == 1
replace year = year+1 // 这样才是用前一年的收益率数据计算sigma
keep Stkcd year sigma_e
compress
save "${PATH}/process/tempfile_sigma_e.dta", replace
use "${PATH}/process/tempfile_sigma_e.dta", clear
merge 1:1 Stkcd year using "${PATH}/process/tempfile_VE.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/tempfile_VD.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/tempfile_ret.dta"
keep if _m == 3
drop _m
foreach var of varlist VE VD ret sigma_e {
drop if `var' == .
}
gen sigma_vit = VE/(VE+VD)*sigma_e + VD/(VE+VD)*(0.05+0.25*sigma_e)
gen DD = (ln((VE+VD)/VD) + (ret-0.5*sigma_vit^2)*1)/(sigma_vit*1)
gen EDP = normal(-1*DD)
keep Stkcd year EDP
compress
save "${PATH}/process/variable_EDP.dta", replace
erase "${PATH}/process/tempfile_VE.dta"
erase "${PATH}/process/tempfile_VD.dta"
erase "${PATH}/process/tempfile_ret.dta"
erase "${PATH}/process/tempfile_sigma_e.dta"10.4.4 step4 完整代码
clear all
set more off
set excelxlsxlargefile on
global PATH "C:/StataClass/chap_paper_corp"
//
// require run file "paper1-step1-read-raw-data.do"
// "paper1-step2-preprocess.do"
// "paper1-step3-variable_compute.do"
use "${PATH}/process/variable_EDP.dta", clear
replace year = year-1
rename EDP f1_EDP
merge 1:1 Stkcd year using "${PATH}/process/variable_FCFC2s.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_Size.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_ILEV.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_ROA.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_Growth.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_CFO_TA.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_TATurnover.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_FSH.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_Outside.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_PPE.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_SOE.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_Age.dta"
keep if _m == 3
drop _m
merge 1:1 Stkcd year using "${PATH}/process/variable_Vol.dta"
keep if _m == 3
drop _m
keep if exp(Age) >= 10
save "${PATH}/process/data.dta", replace 10.5 练习
1.本次作业需要参考论文《科创板注册制如何提升IPO定价效率?——来自双重差分模型的因果识别证据》,尝试论文中的7个指标。我们对题目中的样本筛选做了一些简化。 该论文发表于期刊《金融研究》204年底5期,你可以通过链接找到该论文,点击下载旁边的PDF链接获取论文全文,PDF格式的文件在课程的QQ群内也可以找到。
本练习相关的数据集有:
TRD_Co.xlsx,(对应的变量说明文件是TRD_Co[DES][xlsx].txt)是我国上市公司的基本信息文件。每一条观测值是一家上市公司的基本信息。IPO_Ipobasic.xlsx(对应的变量说明文件是IPO_Ipobasic[DES][xlsx].txt)是A股上市公司首次公开发行(IPO)基本信息表。每一条观测值代表一家上市公司ipo的基本信息。(该数据集中,股票代码为600018的上市公司有两条上市记录,其余每一个股票代码都仅对应一条上市记录)IPO_IpoBalance.xlsx(对应的变量说明文件是IPO_IpoBalance[DES][xlsx].txt),上市公司iop前的资产负债表文件。IPO_IpoIncome.xlsx(对应的变量说明文件是IPO_IpoIncome[DES][xlsx].txt),上市公司ipo前的利润表文件。 上述三个文件IPO_IpoBalance.xlsx、IPO_IpoIncome.xlsx、IPO_IpoCashFlow.xlsx分别是上市公司ipo上市招股前的财务报表,按照规定,上市公司必必须公布上市前三年的年度报表,除了必须公布的近三年年报外,也有一些上市公司会公布更多数量的报表,例如季度报表或者更早年份的报表。在这三个数据文件中,(变量Accper可以看出来)。new_stock_TRD_Dalyr.xlsx,(对应的变量说明文件是TRD_Dalyr[DES][xlsx].txt),2019-2022年间上市的沪深A股股票从上市首日到2023年底的日度交易数据。
上述所有数据集都可以在压缩包chap_paper_corp_exc_q1_data.zip内找到。该压缩包文件可以在班级qq群文件的data目录内获取。
请先阅读论文的“摘要”和“实证研究设计”部分,然后利用给定的数据文件(接下来会有说明)和每个小题中的提示,逐步完成指标复现工作。
(a)[数据准备] 请将所有的数据文件读入Stata,第1行作为变量名、第2行和第3行作为变量标签,尽可能转换为数值型变量,根据excel的文件名对应保存为dta文件(例如数据文件是A.xlsx,处理后的文件保存为A.dta,接下来所有的数据处理请从这些dta文件出发;
(b)[样本初步筛选] 请基于文件TRD_Co.dta和文件IPO_Ipobasic.dta中的变量信息,逐步筛选出满足如条件的公司:
- 上证主板、深证主板、科创板的上市公司(可以根据文件
TRD_Co.dta中的变量Markettype筛选) - 上市日期在2019-07-01到2022-12-31之间的上市公司(可以根据文件
TRD_Co.dta中的变量Listdt筛选); - 非金融行业的上市公司(可以根据文件
TRD_Co.dta中的变量Indnme进行筛选) - 剔除“转板上市”的公司(可以根据文件
IPO_Ipobasic.dta中的变量Ipotype进行筛选)
(c)[计算招股前财务指标] 分别计算如下几个财务指标,默认都是上市前最近一期年报(例如,上市公司688001的招股日期是2019-06-27,上市前三年的年报会计日期(Accper)分别是2016-12-31,2017-12-31,2018-12-31,需要计算的财务指标是2018-12-31的数值):
- 变量
lnSize: 定义为公司招的总资产(单位:元)的自然对数(总资产在资产负债表文件IPO_IpoBalance.dta中的资产总计科目); - 变量
lnRevenue: 定义为公司招股前营业收入(单位:元)的自然对数(营业收入在利润表文件IPO_IpoIncome.dta中的营业收入科目) - 变量
lnAge:企业年龄,定义为上市当年(Listdt变量所对应年份,该变量可以在文件TRD_Co.dta中找到)距离公司成立年份(Estabdate对应的年份)的年数的自然对数 - 变量
ROA:总资产收益率,招股前公司净利润除以招股前公司总资产的比例(净利润在利润表IPO_IpoIncome.dta中的净利润科目;总资产在资产负债表文件IPO_IpoBalance.dta中的资产总计科目)。 - 变量
RevenueGrowth:营业收入增长率,定义为当年营业收入相比前一年营业收入的增长率(营业收入在利润表文件IPO_IpoIncome.dta中的营业收入科目) - 变量
FixedRatio:固定资产占比,定义为固定资产占总资产的比例(固定资产在资产负债表文件IPO_IpoBalance.dta中的固定资产净额科目,总资产在资产负债表文件IPO_IpoBalance.dta中的资产总计科目)。
上述财务指标,最终将得到6个文件,每一个指标保存一个文件,其中有2个变量:Stkcd和对应的财务指标(lnSize、lnRevenue、\cdots),且每股票有且仅有一个观测值,对应的文件名使用核心变量名命名,即lnSize.dta,lnRevenue.dta \cdots
(d)[计算IPO抑价率] 与原论文中的定义相同,IPO抑价率Return的定义分“科创板股票”和“其他板块股票”。 对于科创板股票来说,抑价率定义为上市首日收盘价格相对于股票发行价格的增长率:
Return = \frac{\text{新股上市首日的收盘价}-\text{发行价}}{\text{发行价}}
对于沪深A股主板的股票而言,股票定义为从上市首日开始,直到第一个涨停板打开时的累计回报率:
Return = \frac{\text{新股上市后首个收盘未涨停日的收盘价}-\text{发行价}}{\text{发行价}}
将计算好的指标保存在文件Return.dta中,改文件包含两个变量:Stkcd和Return。 之所以这样计算非科创板股票(即沪深A股主板含中小板股票)的抑价率,是因为A股市场对于IPO的定价存在一些管制措施、以及交易所的股票涨跌停板制度。一些新股定价过低或者市场行情过于火热,新股上市后连续一字涨停。 本题目样本中的A股市场的涨跌停板制度规则如下: - 科创板股票:上市前5日不设涨跌幅,后续每日涨跌幅限制为20% - 主板、创业板股票:上市首日涨幅44%、跌幅36%,后续每日涨跌幅限制为10%。
因此对于非科创板股票可以通过每日的股票收益率(考虑分红再投资的回报率dretwd)是否大于0.099来判定当日是否涨停、上市首日的涨幅是否超过43%来判断上市首日是否涨停。 注意,不同的股票上市后连续涨停的天数并不一样,有些连续10天以上,有些在5天以内,甚至有有些新股上市当天就未能涨停(达到44%)
下面展示了一个连续涨停的示例。
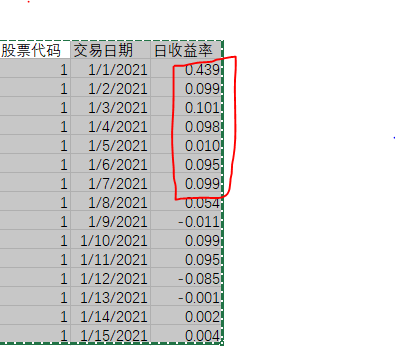
在这个例子中,我们假设股票1的上市日期是2021年1月1日,第3列中是该股票从上市首日到2021年1月15日(这里忽略了周末,假定每天都可以交易——但再次强调这不是真实的情况,真实的股票交易在节假日因为休市没有交易数据)之间的日收益率,第1天到第7天之间连续涨停(首日收益率大于0.43,第6到第7天收益率>0.099),在第8天未涨停(即第8天涨停板打开)。因此该股票的新股收益率(Return)就是从第1天到第8天的累计日收益率 Return=(1+0.439)*(1+0.099)*\cdots*(1+0.054)-1。虽然股票1后续再1月10日和1月11日再次涨停,但由于1月8日和1月9日并未涨停,但这两天不能计入IPO抑价率指标Return中。
(e)[合并样本并进一步筛选] 将第(3)小问中得到的6个财务指标文件、第(4)小问中的抑价率指标文件合并在一起(一对一 merge合并);然后删除6个财务指标缺失和抑价率指标缺失的样本,再然后将所有指标在1%的水平上进行缩尾处理;最后将数据文件保存为文件exc1_data.dta。(提示:1%缩尾处理是指将变量取值小于1%分位数的取值全部替换为1%分位数值、将大于99%分位数的取值全部替换为99%分位数,可以使用第三方命令winsor2完成,你可以通过命令ssc install winsor2安装它,它的语法结构为:winsor2 var1 var2 var3, replace cuts(1 99))。另外,在最终提交的代码中,请将ssc install winsor2注释掉,因为安装命令不需要反复执行
(f)[描述性统计] 将第(5)小问中得到的所有指标,生成描述性统计表格和相关系数表格。(本题需要用到 章节 8 中的内容。 描述性统计表格要求:
- 通过第三方命令
sum2docx将结果直接生成到当前工作路径下的summary.docx文件中 - 报告如下统计量——样本量(
N)、均值(mean)、标准差(sd)、1分位数(p1)、25分位数(p25)、中位数(median)、75分位数(p75)、99分位数(p99) - 除了样本量外,其余统计量保留2位小数(对应的fomat格式为
%9.2f) - 添加Note,内容是你的姓名和学号,例如:张三 10011001
- 添加标题,内容是“表1 主要指标描述性统计表”
相关系数表格要求:
- 通过第三方命令
corr2docx将结果直接生成到当前工作路径下的correlation.docx文件中 - 只报告Pearson 相关系数,不报告Spearman相关系数
- 标注显著性水平,* 代表p值 不超过0.1但大于0.05, ** 代表p值不超过0.05但是大于0.01,*** 代表p值不超过0.01;
- 添加Note,内容是你的姓名和学号,例如:张三 10011001
- 添加标题,内容是“表2 主要指标相关系数表”
当然,不一定所有的研究都是“公司x年度”的结构,可能是“公司x季度”,亦可能是“公司x半年度”,这取决于研究议题中使用的数据。大量研究使用年度数据,一个原因可能与数据质量有关:我国的上市公司财务报表可以分为季度报表、半年度报表和年度报表,半年度和年度报表是经过审计的,但是季度报表是未经过审计。↩︎
控股股东信息数据从2003年开始。月度交易数据可以到2022年的近期月份。↩︎
为了演示方便,我们提供给大家的数据只包含了计算变量所必须的指标。实际中CSMAR提供的数据变量不止这些。↩︎
金融类企业和非金融类企业的的营业收入模式完全不同,你会看到在这个数据中,金融类上市公司的营业收入都是缺失值;CSMAR中提供了另一个字段:营业总收入,金融类企业可以使用这一指标。但是在我们参照的这篇论文中,研究对象是非金融类上市公司,因此使用指标营业收入即可。↩︎