在本章中,我们将系统学习变量相关的命令。包括:如何生成新的变量,变量命名的规则和一般原则、如何修改变量的取值、字符型和数值型变量的概念、字符型变量和数值型变量的互相转换。
与变量相关的基础知识
数据、变量和数据集
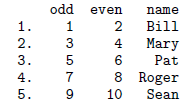
前文介绍过,Stata中的数据以二维表的形式展示,每一行是一条观测 (observation),每一列是一个变量 。不同的变量通过变量名来区别彼此(换句话说,一个数据集中,变量名不可以出现重复)。每行的观测值的行号取值从1一直递增到_N。下面的数据集就包括了10以内的5个奇数和五个偶数的变量,以及一个字符型的变量
在这个文件里,观测值的行数依此是1,2,…,5。3个变量依此是:odd, even, name。
数据集是数据加上标签labelings、显示格式formats、注释notes,以及特性characteristics等元素在一起。直观上来看数据集对应的就是我们的数据文件(后缀名为.dta)
命令
生成一个新的变量的命令是generate和egen,egen是generate的扩展,区别是egen只能使用函数来生成新变量,而generate既可以通过函数、也可以通过变量之间的运算生成新的变量。
改变变量的定义或(部分)取值的命令是replace。注意在Stata中,单独一个等号(=)代表的不是关系运算或者逻辑关系中的等于,而是赋值符号。代表将等号右侧的内容赋值给等号左侧的内容。
命名规则
对于Stata中的变量名称的要求:
除了以下条件外,变量名可以是任意字符、数字、下划线的组合。
不能以数字开头
不能使用系统保留的名称: _all, _b , byte, _coef, _cons, double, float, if, in, int, long, _n, _N, _pi, _rc, _se, using, with…
最多包括32个字符
因为Stata中保留了大量以下划线“_”开头的系统变量,所以自己生成变量时(最好)不要以下划线开头。
clear all set obs 100 // 设定数据共100行 generate x = 1 generate y = _n gen x1 = x/1gen x_m_1 = x-1gen ln_y = ln (y )gen x2 = x^2 gen z = x/y replace x = x + 1 gen y_p1 = exp (ln_y)+1replace x = 3
变量类型
数据的变量的数据类型可以分为两类:数值型和字符型。数值型就是类似1,-5等整数、1.243等小数的数字。字符型就是类似张三、李四等文字。Stata中表示字符的时候需要用引号引起来,以区别于变量名称。
数值型变量
数值中可能包含有:符号(标识正负)、整数部分、小数点、小数部、是科学技术法的符号e或者E、一个有符号的指数。数值中不得出现逗号(comma),例如1024不能写成1,024。以下都是合法的数值类型:
display 5 di -5di 5.2 di 0.5 di .5 di 5.2e+2 // 5.2*10^2=502 di 5.2e+12 // 含义是 5.2*10^12 di 2.5e-2 // 含义是 1/(2.5*10^2) di 2.5e-12 // 1/(2.5*10^12)
缺失值missing value
在Stata中,缺失值是一种特殊的数值,用英文句号.来表示。缺失值代表不存在的数值,例如任何数除以0的结果都是缺失值、负数的对数值也都是缺失值。另外,缺失值的任何运算结果仍然是缺失值。
另外一个需要注意的点是在Stata中,缺失值.大于所有的非空数值,也就是 \text{All Number} < .
因此,10 < .这个逻辑表达式的结果是True(逻辑真)。
除了上面介绍的一般缺失值.外,Stata中还引入了更多的缺失值:.a, .b,.c,…,.z,他们都可以代表缺失值,实际数据调查中可以将这些符号赋予不同原因造成的缺失。Stata中还对这些缺失值的大小引入了如下规则:
all nonmissing numbers < . < .a < .b < ... < .z
具体内容请通过help missing value查看帮助文档的说明。
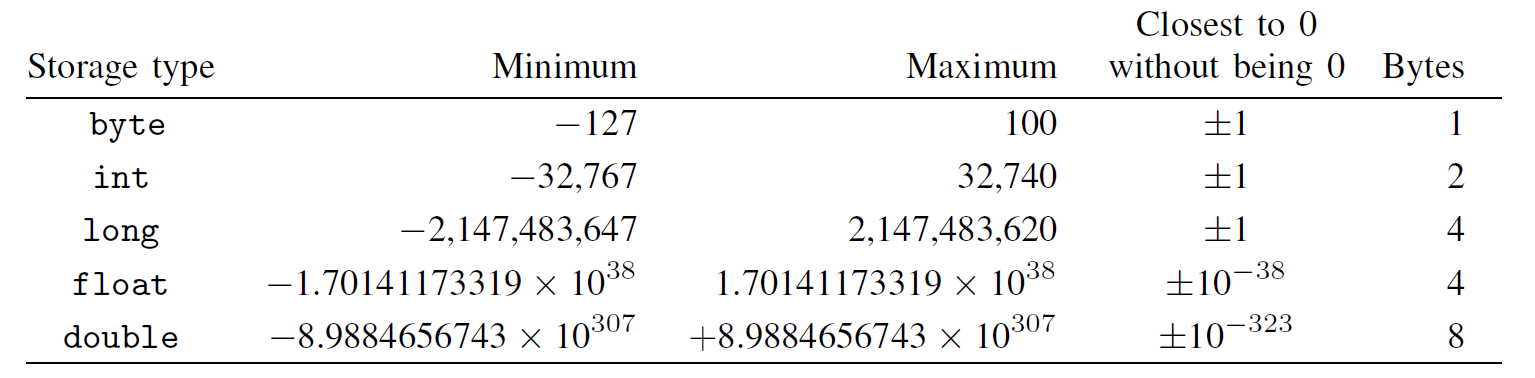
数值型变量的存储类型
数值型变量的存储类型包括:
其中,byte(字节整数型)、int(整数型),long(长整数型)等三种类型都是整数,float(浮点型)和double(双精度型)都是小数。精度越高,对内存空间的占用越多,程序运行速度会越慢。
关于数据的存储类型,一般不用特别设定,Stata的默认设定即可。Stata会自动采用当前最优的存储方案,另外命令compress可以自动对当前数据进行压缩。
日期型变量
在Stata中,日期型变量是整数型数值变量中的一种。1960年1月1日是第0天,用数字0表示;1960年1月2日是第1天,用数字1表示;1959年12月31日是第-1天,用数字-1来表示。2022年10月1日是第22919天,用数字22919表示。
时间型变量也是类似的,对于日期型、日期时间型数据的讨论,我们将放在函数章节单独进行介绍。
字符串变量
字符变量的类型
字符变量可以是任何内容,常见的字符都是以字母(或者汉字)和一些特殊符号组成,例如“地名《籍贯》变量,住址、职业等”,我们通常以双引号(注意是英文状态下)来表示字符(串)。然而,字符也可以是由纯数字构成,例如字符"12345",注意它和数值12345是完全不同的。
在Stata14之前的版本中,字符串最大程度是244个字符。一般用str#来表示字符长度,例如str20就代表有20个字符。在Stata14和以后的版本中,引入了长字符串的变量类型,表示为strL,并不限定字符的长度大小,用于读入长文本,例如个人简历等信息。
display "Apple" di "apple" assert "apple" != "Apple" // assert命令用于判断逻辑表达式结果是True还是False,Stata区分大小写 di " apple" // 注意,空格也是一种符号,也可以放在字符串中 di "apple " di "app le" di "apple_" //下划线也可以加入字符串 di "" // 空串,没有任何内容的字符串,类似集合中空集的概念 di "125.7" di "12345" di "Stata课程很有意思" di "$234.56" di "¥200.23"
. display "Apple"
Apple
. di "apple"
apple
. assert "apple" != "Apple" // assert命令用于判断逻辑表达式结果是True还是False
> ,Stata区分大小写
. di " apple" // 注意,空格也是一种符号,也可以放在字符串中
apple
. di "apple "
apple
. di "app le"
app le
. di "apple_" //下划线也可以加入字符串
apple_
. di "" // 空串,没有任何内容的字符串,类似集合中空集的概念
. di "125.7"
125.7
. di "12345"
12345
. di "Stata课程很有意思"
Stata课程很有意思
. di "$234.56"
$234.56
. di "¥200.23"
¥200.23
.
需要指出的是,在Stata内部,是区分大小写的,因此"apple"和"Apple"是两个字符串。另外字符串"125.7"是可以和数值125.7互转,类似的,字符串"12345"和数值12345也是可以互转的,方法是使用real()函数和destring命令,我们将会在本章的 小节 4.5
字符变量的运算
字符变量的大多数操作主要是通过函数来完成,将会在后续课程中具体讲解。这里我们首先讲解字符串的合并运算符“+”,可以把两个字符型变量合并在一起:
clear all set obs 3gen x = "a" gen y = "b" gen z = x+y gen z1 = x+" " +y gen z2 = x+"-" +y list
变量的自定义显示
变量的显示格式
变量的显示格式是指在结果窗口中显示出来的样式,显示格式和变量的取值是有区别的。例如数字可以控制小数点后的位数:12.34可以显示为12.340,12.3400000等;字符变量可以控制显示的长度、对齐方式等。可以通过help format系统学习。
clear webuse census10describe list in 1/8format state %-14s // s代表字符,-14表示左对齐的14个字符长度 list in 1/8format region %-8.0g // list in 1/8format pop %12.0gc // c是comma的意思 list in 1/8format medage %8.1flist in 1/8
标签label
标签大致有:数据标签(data label)、变量标签(variable label)、和取值标签(value label)这三类。可以通过help label查看帮助文档。
数据标签和变量标签较好理解,是对数据和变量的说明,对应的语法是:label data “data_labesl ”和label variable varname “variable_label ”。设定之后可以通过describe查看数据的标签和变量的标签。
取值标签在默认的Stata17数据浏览器窗口中是蓝色字体,可以使用list dir查看value label name,然后通过label list libname 查看。以auto.dta中foreign变量的取值标签origin为例,下面的代码展示了如何查看它的情况:
sysuse auto, clear label dir label list origin
. sysuse auto, clear
(1978 automobile data)
. label dir
origin
. label list origin
origin:
0 Domestic
1 Foreign
.
习题
1.[本题目基于第二章《文件操作》课后习题第一题得到的数据文件index_trade_data202101.dta]。基于数据文件index_trade_data202101.dta,实现如下功能:
将收盘价、开盘价、最高价、最低价转换为数值型变量,要求用数值替换原变量的字符内容
生成新变量ln_收盘价,定义为收盘价的自然对数
生成新变量价差,定义为最高价和最低价的差值除以最高价和最低价的平均值
给出每一个交易日内价差变量的描述性统计